"Top 10 Machine Learning Projects for 2025: Build, Learn & Boost Your Portfolio (with Code)"

Machine Learning is not just a buzzword; it's the invisible force powering the very fabric of every industry today – from revolutionizing healthcare diagnostics and optimizing financial markets to personalizing entertainment and driving autonomous systems. In the dynamic landscape of 2025, where AI advancements are accelerating at an unprecedented pace (think of the impact of Generative AI, MLOps, and Edge AI), the ability to translate theoretical knowledge into tangible, smart, real-world applications is paramount. This practical expertise now far outweighs the value of mere certificates or academic theory alone.
This blog isn't just a list; it's your definitive guide to the Top 10 Machine Learning Projects for 2025. Each project has been meticulously selected to reflect emerging trends and in-demand skills, offering you a comprehensive learning experience. You'll find detailed overviews, step-by-step implementation instructions, and direct links to functional code repositories (often on GitHub). This resource is perfectly tailored for ambitious final-year students looking to capstone their education, career switchers aiming to make a significant leap into the AI domain, or seasoned AI enthusiasts eager to refine their craft and genuinely "go pro" by building an undeniable portfolio.
Why ML Projects Matter More Than Ever in 2025:
The job market for Machine Learning and AI professionals is fiercely competitive, yet brimming with opportunities for those who can truly demonstrate their capabilities. Here's why hands-on projects are your strongest asset:
- Hands-on ML portfolios = 2X more interview calls: In 2025, employers are inundated with resumes. A well-curated portfolio showcasing real-world projects acts as a powerful differentiator. It provides concrete proof of your problem-solving abilities, technical proficiency, and initiative, cutting through the noise and significantly increasing your chances of landing that crucial interview. It signals you're a builder, not just a learner.
- Each project showcases your ability to build, deploy, and manage: Beyond just model training, modern ML roles demand an understanding of the entire lifecycle – from data ingestion and preprocessing to model deployment, monitoring (MLOps), and scalability. Each project in this guide is designed to walk you through these end-to-end processes, giving you practical experience in the full development pipeline that employers actively seek.
- They demonstrate real-world problem-solving, not just academic knowledge: The transition from theoretical concepts to practical implementation often involves grappling with messy data, unexpected challenges, and optimizing for performance. Projects force you to confront these real-world complexities, developing critical debugging skills, data intuition, and the ability to adapt algorithms to specific business use cases. This practical acumen is what truly makes you valuable in an industry setting.
- Stay Relevant with Emerging Technologies: The ML landscape evolves rapidly. Working on diverse projects exposes you to cutting-edge algorithms, frameworks (like advanced deep learning architectures, Generative AI models), and tools (e.g., cloud platforms, MLOps tools) that are becoming standard in 2025. This continuous learning through building keeps your skills sharp and relevant.
- Networking & Collaboration Opportunities: Sharing your projects on platforms like GitHub can lead to valuable feedback, collaboration opportunities, and even direct recruitment by companies impressed with your work. Your code becomes your professional handshake.
What Each Project Includes:
To ensure a comprehensive learning and showcasing experience, every project in this guide comes equipped with the following:
- 🔍 Overview (Detailed + Real-World Use Case): A clear explanation of the project's purpose, the problem it solves, and its direct applicability in current industries. This helps you understand the "why" behind the "what."
- 🧠 Key Skills You’ll Learn: A breakdown of the specific technical and problem-solving skills you will acquire or reinforce, such as data cleaning, feature engineering, model selection, hyperparameter tuning, API integration, deployment strategies, etc.
- 🧪 Core Algorithms Used: Identification of the primary machine learning algorithms (e.g., Convolutional Neural Networks, Random Forests, Transformers, Reinforcement Learning, Clustering) central to the project's solution.
- 🛠️ Essential Tech Stack: A list of the programming languages, libraries, frameworks (e.g., Python, TensorFlow, PyTorch, Scikit-learn, FastAPI, Streamlit, Docker, AWS/GCP services), and tools necessary for implementation.
- 🔩 Step-by-Step Build Guide: A clear, actionable roadmap guiding you through the entire project development process, from data acquisition and preprocessing to model training, evaluation, and deployment.
- 🔗 GitHub Link: Direct access to the complete, well-documented code repository, allowing you to easily fork, experiment, and customize the project to your needs. This is crucial for employers to review your work.
Table of Contents:
- 🚀 Stock Price Predictor using LSTM
- 📰 Fake News Detection using NLP
- 📄 Smart Resume Scanner with NLP + Streamlit
- 🤖 Machine Learning Chatbot using Rasa or ChatterBot
- 📈 Sales Forecasting with Linear Regression
- 🧬Disease Prediction System using Machine Learning
- 😷 Face Mask Detection using Computer Vision & Deep Learning
- 📑 Document Scanner with OCR and ML Enhancement
- 🎵 Music Genre Classification using Deep Learning (CNN + Audio Analysis)
- 🎥 Movie Recommendation System (Content-Based + Collaborative Filtering)
🚀 Stock Price Predictor using LSTM
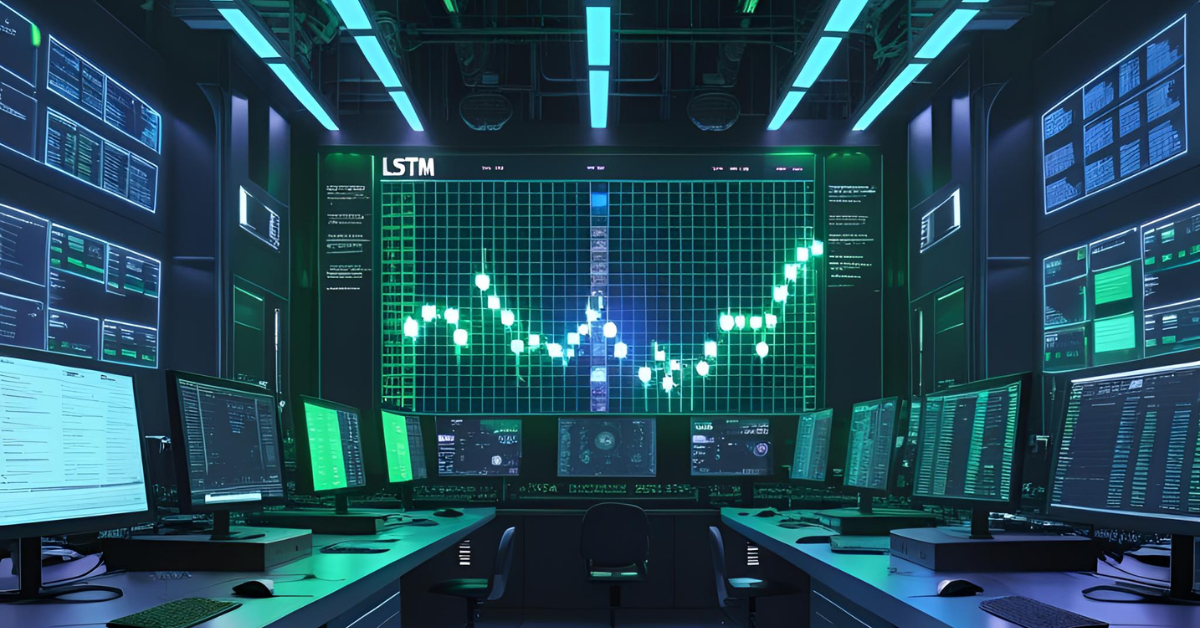
- 🔍 Overview: Mastering Predictive Analytics for Financial MarketsStock market forecasting remains one of the most challenging yet high-value applications of machine learning in various domains, including fintech, algorithmic trading, quantitative analysis, and business analytics. This project provides a practical pathway to creating an intelligent predictive model using Long Short-Term Memory (LSTM) neural networks. LSTM is a specialized type of Recurrent Neural Network (RNN) uniquely suited for time-series data due to its internal memory cells that can selectively remember or forget information over long sequences. This capability allows the model to learn long-term dependencies and complex patterns inherent in historical stock price movements, which traditional models often miss.The primary goal is to predict future stock closing prices based on historical data, specifically focusing on previous closing prices. By building and evaluating this model, you will gain hands-on experience with the entire time-series forecasting pipeline. The ultimate output will be a visual representation comparing the model's predictions against actual stock prices, allowing for intuitive assessment of its performance. While perfect prediction in a volatile market is impossible, this project equips you with the foundational techniques for building robust time-series forecasting systems.
- 🧠 Skills You’ll Learn:Time-series data preprocessing: Handling sequential data, creating lagged features, and preparing data for neural networks.Deep learning using LSTM: Understanding the architecture and application of LSTM layers for sequential modeling.Model tuning and performance evaluation: Optimizing hyperparameters, monitoring training, and assessing model accuracy using appropriate metrics for regression.Data visualization using Matplotlib: Effectively presenting time-series predictions and actual trends for clear interpretation.Introduction to financial data handling: Working with real-world stock market data.
- 🧪 Algorithms Used:LSTM (Long Short-Term Memory Neural Networks): The core deep learning architecture for capturing temporal dependencies.MinMax Scaling: A crucial data normalization technique to scale features to a specific range (e.g., 0-1), which is essential for neural network performance.Mean Squared Error (MSE): The standard loss function for regression problems, measuring the average squared difference between actual and predicted values.Adam Optimizer: An adaptive learning rate optimization algorithm widely used for training deep neural networks efficiently.
- 🛠️ Tech Stack:Python: The primary programming language.Keras / TensorFlow: High-level API (Keras) built on TensorFlow for building and training deep learning models.Pandas: For efficient data manipulation and analysis (e.g., reading CSVs, handling DataFrames).NumPy: For numerical operations, especially array manipulation, essential for preparing data for LSTM.Matplotlib: For creating static, animated, and interactive visualizations in Python, crucial for plotting stock trends.yfinance (Yahoo Finance API): A convenient library to fetch historical stock data programmatically.
- 🔩 Step-by-Step Build:Install Dependencies:Explanation: These libraries provide the necessary tools:
pandasandnumpyfor data handling,matplotlibfor plotting,tensorflowandkerasfor building and training the deep learning model, andyfinancefor easy access to historical stock data.Import Stock Data:Use theyfinancelibrary to download historical stock data for a chosen company.Example: Fetch data for a well-known stock like Apple (AAPL), Tesla (TSLA), or Microsoft (MSFT) for a specific period (e.g., the last 5-10 years).Consideration: Focus on theCloseprice column as the primary feature for prediction, as it represents the final trading price of the stock on a given day.Data Preprocessing:Feature Selection: Isolate theCloseprice column from your downloaded dataset.Train-Test Split: Divide your prepared data into training and testing sets. A common split for time series is to use an earlier portion for training and a later, unseen portion for testing to simulate real-world prediction.Build LSTM Model:One or moreLSTMlayers: Define the number of units (neurons) andinput_shapefor the first layer (e.g.,(n_days, 1)). Considerreturn_sequences=Truefor intermediate LSTM layers if stacking multiple, andreturn_sequences=Falsefor the last LSTM layer before a Dense output.Dropoutlayers: (Optional but recommended) To prevent overfitting by randomly setting a fraction of input units to 0 at each update during training time, which helps improve generalization.A finalDenselayer: With one unit and a linear activation function for the single price prediction output.Use themodel.compile()method.Optimizer:adamis a good general-purpose choice for its adaptive learning rate.Loss Function:mean_squared_error(mse) is appropriate for regression tasks where you're predicting continuous values.Train the Model:Use themodel.fit()method to train your LSTM model.Specifyepochs(number of times the model will go through the entire training dataset) andbatch_size(number of samples per gradient update).Include avalidation_splitto monitor performance on unseen data during training and detect overfitting.Prediction & Visualization:Predict on Test Data: Usemodel.predict()on yourX_testdataset to get the model's predictions.Evaluate Quantitatively: Calculate quantitative metrics like Root Mean Squared Error (RMSE) to assess the model's accuracy more rigorously. - Optional: Wrap it in a Streamlit Dashboard or Flask App for UI.Benefit: Building a simple user interface allows for interactive demonstrations of your model. Users can input a stock ticker or date range, and the application can fetch data, make predictions, and display results dynamically. This transforms your script into a more engaging and presentable product, ideal for showcasing in a portfolio or for practical application.Streamlit: A powerful, easy-to-use library for creating web apps with Python, perfect for data science and ML projects.Flask: A lightweight web framework for building more traditional web applications.
Plot Actual vs. Predicted Prices: Use matplotlib.pyplot to create a line plot comparing the actual closing prices from your test set with your model's predicted prices. This visual comparison is key to evaluating the model's performance and identifying trends it captured or missed.
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 8))
plt.title('Stock Price Prediction')
plt.xlabel('Date', fontsize=18)
plt.ylabel('Close Price USD ($)', fontsize=18)
plt.plot(actual_prices_index, y_test_actual, label='Actual Price') # Ensure actual_prices_index corresponds to dates
plt.plot(predicted_prices_index, predictions, label='Predicted Price')
plt.legend(loc='lower right')
plt.show()
Inverse Scale Predictions: Since you normalized the data earlier, you need to "inverse transform" the predictions back to their original stock price scale using the scaler object. This makes the predictions interpretable.
predictions = model.predict(X_test)
predictions = scaler.inverse_transform(predictions)
# Also inverse transform actual test labels for comparison
y_test_actual = scaler.inverse_transform(y_test.reshape(-1, 1))
Optional: Implement EarlyStopping callback from Keras to stop training if the validation loss doesn't improve for a certain number of epochs, preventing overfitting and saving training time.
from keras.callbacks import EarlyStopping
# Optional: early stopping to prevent overfitting
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history = model.fit(
X_train, y_train,
epochs=100, # Start with a reasonable number of epochs
batch_size=32,
validation_split=0.2, # Use 20% of training data for validation
callbacks=[early_stopping] # Add early stopping
)
Compile the Model:
model.compile(optimizer='adam', loss='mean_squared_error')
Use Keras's Sequential API to stack LSTM layers. A typical architecture might include:
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(n_days, 1)))
model.add(Dropout(0.2)) # Example dropout rate
model.add(LSTM(units=50, return_sequences=False)) # Last LSTM layer, return_sequences=False
model.add(Dropout(0.2))
model.add(Dense(units=1)) # Output layer for predicting one value (next day's price)
Reshape Data for LSTM: LSTM layers in Keras expect input data in the format (samples, timesteps, features). Since you're using a single feature (closing price), reshape X accordingly:
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
Create Time-Series Sequences: This is critical for LSTMs. You'll create sequences (or "windows") of past data points as input features (X) and the immediate next data point as the target label (y). For example, if n-days (also known as look_back or timesteps) is set to 60, the model will use the past 60 days' closing prices to predict the 61st day's closing price.
import numpy as np
def create_sequences(data, n_days):
X, y = [], []
for i in range(len(data) - n_days):
X.append(data[i:(i + n_days), 0])
y.append(data[i + n_days, 0])
return np.array(X), np.array(y)
n_days = 60 # Example: using last 60 days to predict next day
X, y = create_sequences(scaled_data, n_days)
Normalization (Scaling): Stock prices can vary significantly in magnitude. Normalize the data using MinMaxScaler from sklearn.preprocessing. This scales the prices to a range between 0 and 1, which helps neural networks converge faster and prevents issues with large gradients.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(closing_prices)
Open your terminal or command prompt and run:
pip install pandas numpy matplotlib tensorflow keras yfinance
Project 1:Stock Price Predictor using LSTM Codes:
🔗 View Project Code on GitHub📦 1. Install Required Libraries
pip install yfinance pandas numpy matplotlib scikit-learn tensorflow
✅ Output: You’ll Get
· A line chart comparing actual vs. predicted stock prices
· A trained LSTM model you can fine-tune or deploy
· A complete pipeline from data fetching to visualization
🔍 Bonus Extensions
· 🎯 Add RMSE as an evaluation metric
· 🔁 Predict multiple steps ahead (multi-output LSTM)
· 🌐 Streamlit app with dropdown for stock selection
· 📈 Candlestick + LSTM hybrid visualization
📉 Sample Output
After training, the script plots Predicted vs Actual stock prices using test data.
🧪 Evaluation Metric
· Loss Function: Mean Squared Error (MSE)
· Scaler: MinMaxScaler
· Model: Two-layer stacked LSTM with dropout
🧰 Next Steps
· Add support for multivariate prediction (e.g., volume, open, high, low)
· Build a Streamlit dashboard
· Deploy as an API with Flask/FastAPI
· Enable multi-day forward forecasting
📚 References
Yahoo Finance: https://finance.yahoo.com/
LSTM Theory: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
💡 This is not financial advice. For educational use only.
2. 📰 Fake News Detection using NLP

- 🔍 Overview: Combatting Misinformation in the Digital Age In 2025, the digital landscape is increasingly saturated with information, but also with a growing torrent of misinformation. Fake news, amplified by sophisticated social media algorithms and the rise of AI-generated content (deepfakes, AI-written articles), poses a significant threat to public discourse, democratic processes, and individual understanding. This project provides you with the practical skills to build a robust machine learning model specifically designed to detect fake news articles based on their inherent textual patterns and linguistic characteristics.You will delve into the critical domain of Natural Language Processing (NLP), learning to clean, transform, and analyze textual data. By building this model, you'll develop expertise vital for applications in journalism-tech (e.g., automated fact-checking), cybersecurity (e.g., identifying malicious propaganda), and policy analysis (e.g., understanding information warfare tactics). The core challenge lies in identifying subtle linguistic cues, stylistic inconsistencies, or unusual word frequencies that differentiate authentic news from fabricated content, even when the topics might appear similar. This project serves as an excellent foundation for understanding how AI can be leveraged to address real-world societal challenges.
- 🧠 Skills You’ll Learn:NLP Text Cleaning and Preprocessing: Master techniques to prepare raw, unstructured text for machine learning, including normalization, noise removal, and tokenization. This is a foundational skill for any text-based ML project.TF-IDF Vectorization for Text Data: Understand how to convert textual data into a numerical format that machine learning models can understand, specifically using TF-IDF to capture the importance of words within documents and across a corpus.Binary Classification with Supervised Learning: Apply supervised learning principles to categorize data into two distinct classes (real vs. fake news), including understanding feature engineering and model selection for classification tasks.Model Evaluation beyond Accuracy: Learn to critically assess model performance using metrics highly relevant to imbalanced datasets often found in real-world scenarios (e.g., fewer fake news examples than real).Deploying Models with Flask: Gain practical experience in taking a trained machine learning model and integrating it into a simple web application, making it accessible for real-time predictions.
- 🧪 Algorithms Used:Logistic Regression: A powerful and interpretable linear model commonly used for binary classification. It serves as a strong baseline for text classification tasks due to its efficiency and ability to handle high-dimensional sparse data (like TF-IDF vectors).TF-IDF (Term Frequency-Inverse Document Frequency): This is not strictly an algorithm but a statistical measure used for vectorization. It reflects how important a word is to a document in a collection or corpus. Words that appear frequently in a document but rarely in the entire corpus get a higher TF-IDF score, highlighting their significance.Evaluation Metrics:Confusion Matrix: A table used to describe the performance of a classification model on a set of test data for which the true values are known. It visually summarizes correct and incorrect predictions.Precision: The proportion of positive identifications that were actually correct. High precision means fewer false positives (classifying real news as fake).Recall (Sensitivity): The proportion of actual positives that were identified correctly. High recall means fewer false negatives (failing to detect fake news).F1-Score: The harmonic mean of precision and recall. It's a useful metric for imbalanced classification problems, providing a balance between precision and recall.
- 🛠️ Tech Stack:Python: The core programming language for data processing, model building, and web development.Scikit-learn: A comprehensive and widely-used library for machine learning in Python, providing tools for preprocessing, model training, and evaluation.NLTK (Natural Language Toolkit): A powerful library for working with human language data, essential for various text preprocessing steps like tokenization and stemming/lemmatization.Pandas: For efficient data manipulation and analysis, particularly when handling datasets loaded from CSVs.Flask: A lightweight and flexible micro web framework for Python, ideal for quickly building and deploying simple web applications to demonstrate your model.
- 🔩 Step-by-Step Build:Collect Dataset:Source: Utilize a publicly available dataset specifically curated for fake news detection, such as the popular Kaggle Fake News dataset. This dataset typically contains news articles along with a label indicating whether they are "real" or "fake."Preparation: Download the dataset (often in CSV format). Load it into a Pandas DataFrame.Challenge Insight: Real-world fake news datasets can be tricky due to evolving tactics, varying definitions of "fake," and potential class imbalance (e.g., more real news than fake). Understanding these challenges is part of the learning process.Text Preprocessing:Objective: Transform raw, noisy text into a clean, normalized format suitable for machine learning.Convert text to lowercase: Standardizes text, ensuring that "The" and "the" are treated as the same word.Remove stopwords, special characters, and URLs:Stopwords: Words like "a," "an," "the," "is" that are very common but carry little semantic meaning for classification. Use NLTK's list of stopwords.Special Characters & Punctuation: Remove symbols, numbers, and punctuation marks that don't contribute to the meaning of the text for classification.URLs: Web links often appear in news articles but are irrelevant for content-based fake news detection.Tokenize and Stem/Lemmatize Text using NLTK:Tokenization: Breaking down text into individual words or "tokens."Stemming (e.g., Porter Stemmer): Reducing words to their root form (e.g., "running," "runs," "ran" all become "run"). This is a rule-based approach.Lemmatization (e.g., WordNetLemmatizer): Similar to stemming but more sophisticated, it reduces words to their base or dictionary form (lemma), ensuring the resulting word is a valid word (e.g., "better" becomes "good"). Lemmatization often provides better results but is computationally more intensive. Choose one based on your preference and experimentation.Implementation Tip: Create a function that encapsulates all these preprocessing steps to apply it consistently across your dataset.Vectorization (Feature Extraction):Concept: Machine learning models understand numbers, not raw text. Vectorization converts text into numerical representations.TF-IDF (Term Frequency-Inverse Document Frequency): Use
TfidfVectorizerfromsklearn.feature_extraction.text.Term Frequency (TF): How often a word appears in a document.Inverse Document Frequency (IDF): A measure of how important a word is across the entire corpus. Words that appear in many documents (like "the") will have a low IDF, while unique or specific words will have a high IDF.Outcome: TF-IDF assigns a weight to each word in each document, reflecting its relevance. This creates a sparse numerical matrix where rows are documents and columns are unique words (features).Important: Fit theTfidfVectorizeron your training data only to prevent data leakage, then transform both training and test data.Model Training:Dataset Split: Divide your vectorized dataset into training and testing sets (e.g., 80% for training, 20% for testing) usingtrain_test_splitfromsklearn.model_selection. This ensures you evaluate the model on unseen data.Train Logistic Regression Classifier: Instantiate and train aLogisticRegressionmodel fromsklearn.linear_modelon your training data.Hyperparameter Tuning with GridSearchCV:Purpose:GridSearchCVhelps in finding the optimal hyperparameters for your model. Instead of manually trying different settings, you define a "grid" of parameter values, andGridSearchCVsystematically tests all combinations using cross-validation to find the best performing set.Example Hyperparameters for Logistic Regression:C(inverse of regularization strength),penalty(L1 or L2 regularization).Benefit: Leads to a more robust and better-performing model.Evaluation:Predictions: Use your trained model to make predictions on theX_testdata.Performance Metrics:Calculate Accuracy: The overall percentage of correctly classified instances.Calculate Precision, Recall, and F1-Score: These are crucial for fake news detection, as an imbalanced dataset (e.g., many real news, few fake news) can lead to high accuracy even if the model performs poorly on the minority class (fake news).High Precision means your model doesn't often flag real news as fake (minimizing false alarms).High Recall means your model catches most of the actual fake news (minimizing missed fake news).F1-Score provides a balanced view.Visualize Confusion Matrix: Generate and display a confusion matrix. This visual representation will clearly show:True Positives (correctly identified fake news)True Negatives (correctly identified real news)False Positives (real news incorrectly classified as fake)False Negatives (fake news incorrectly classified as real)This helps in understanding where your model is making errors.Build Web App with Flask:Objective: Create a user-friendly interface to demonstrate your model's capabilities without needing to run Python scripts directly.Flask Setup: Create a simple Flask application.Model Loading: Save your trainedTfidfVectorizerandLogisticRegressionmodel (usingjobliborpickle) after training, and load them into your Flask app when it starts. This avoids retraining the model every time.User Interface: Design a basic HTML form (within Flask templates) where users can paste or type a news article's text.Prediction Endpoint: Create a Flask route that accepts the user's input text, preprocesses it using your saved vectorizer, feeds it to the loaded model for prediction, and returns "Real News" or "Fake News" back to the user.Interaction: The user submits text, the Flask backend processes it using the ML model, and the result is displayed on the webpage.Optional: Add a News API for Real-time VerificationEnhancement: Integrate with a news API (e.g., NewsAPI, GNews API, or even a custom web scraper for specific sources).Workflow: Instead of manual text input, the user could enter a news headline or topic. Your Flask app would then use the API to fetch related articles. For each fetched article, your model could make a prediction, potentially offering a "confidence score" or cross-referencing multiple sources.Benefit: This adds a layer of real-world applicability and demonstrates skills in API integration and automated information retrieval, making your project even more impressive.
Project 2: Fake News Detection using NLP Codes:
🔗 View Project Code on GitHub📊 Dataset
Uses the Fake News Dataset on Kaggle or a custom CSV with text and label columns.
🚀 Ready to transform your curiosity for data into a career-defining edge?
At Huebits, we don’t just teach Data Science—we empower you to analyze, predict, and lead with hands-on experience, real-world capstone projects, and cutting-edge tools like Python, Scikit-learn, Pandas, TensorFlow, Power BI, and FastAPI.
🧠 Whether you're a student, analyst, or future AI leader, our Industry-Ready DS, AI & ML Program is crafted to make you future-proof. Master machine learning, data analytics, AI-driven solutions, and full-stack deployment—all in one immersive, career-launching journey.
🎓 Next Cohort starts soon!
🔗 Join Now to claim your seat and take the first step into India’s booming ₹800 billion+ AI & Analytics ecosystem.
3. 📄 Smart Resume Scanner with NLP + Streamlit
- 🔍 Overview: Navigating the AI-Powered Hiring Landscape of 2025The traditional hiring process is undergoing a significant transformation, with AI-powered Applicant Tracking Systems (ATS) now serving as the first line of defense for companies worldwide. These sophisticated systems automatically filter and rank candidates, often before a human recruiter even glances at a resume. This project empowers you to build your own Smart Resume Scanner, a powerful tool designed to mimic the functionalities of these modern ATS.This intelligent system will enable you to extract critical data from resumes (specifically PDF documents), analyze a candidate's skills and experience against specific job descriptions, and ultimately score candidates based on their relevance. Beyond just ranking, the scanner can provide valuable, actionable feedback to job seekers, highlighting areas where their resume could be optimized to better match a target role.This project is ideal for individuals interested in HR tech startups, aiming to build a compelling portfolio piece showcasing practical NLP applications, or for Machine Learning learners seeking hands-on experience with real-world use cases in a high-impact domain. You'll tackle challenges like unstructured data extraction, natural language understanding, and user interface development, gaining a deep understanding of how AI is reshaping recruitment.
- 🧠 Skills You’ll Learn:Named Entity Recognition (NER): A fundamental NLP technique to identify and classify key information (entities) in text, such as names, organizations, locations, and crucially, specific skills or qualifications within a resume.Keyword Extraction and Vector Similarity: Learn how to identify important terms and phrases from both resumes and job descriptions, and then use vector space models to measure the semantic similarity between these documents. This is the core of "matching."Resume Parsing and PDF Handling: Master techniques for programmatically extracting raw, usable text from various PDF resume formats, which can be challenging due to diverse layouts and embedded elements.Text Preprocessing for Unstructured Data: Refine your skills in cleaning and normalizing messy, real-world text data, including handling resume-specific quirks like bullet points, abbreviations, and varied formatting.Web UI Development using Streamlit: Gain practical experience in building interactive, user-friendly web applications in Python without needing extensive front-end development knowledge, making your project accessible and presentable.
- 🧪 Algorithms Used:TF-IDF (Term Frequency-Inverse Document Frequency) for Text Vectorization: A statistical method used to convert text documents (resumes and job descriptions) into numerical feature vectors, emphasizing words unique and important to each document.Cosine Similarity for Resume vs. Job Match: A metric that measures the cosine of the angle between two non-zero vectors. In this context, it quantifies the similarity between a resume's TF-IDF vector and a job description's TF-IDF vector, yielding a score (typically between 0 and 1) representing the degree of match.Named Entity Recognition (NER) models (from SpaCy): Pre-trained deep learning models within the SpaCy library that can identify and categorize entities like 'PERSON', 'ORG', 'GPE' (geopolitical entity), and can be fine-tuned or augmented for domain-specific entities like 'SKILL'.Regular Expressions (Regex) for Specific Pattern Detection: Powerful string matching patterns used to reliably extract structured information like email addresses, phone numbers, and potentially specific skill patterns (e.g., "Python (Advanced)").
- 🛠️ Tech Stack:Python: The core programming language for the entire project, from data parsing to model deployment.SpaCy: A highly optimized NLP library for Python, ideal for production-ready text processing tasks like tokenization, part-of-speech tagging, and, critically for this project, Named Entity Recognition.NLTK (Natural Language Toolkit): While SpaCy is powerful for NER, NLTK offers a broader set of tools for foundational NLP tasks like stopwords removal and stemming/lemmatization, often used in conjunction with SpaCy for comprehensive preprocessing.PyPDF2 / pdfminer.six: Libraries specifically designed for extracting text and metadata from PDF files. PyPDF2 is generally simpler for basic text extraction, while pdfminer.six offers more advanced capabilities for layout analysis if needed.Scikit-learn: Provides essential tools for text vectorization (TF-IDF), similarity calculations, and potentially other classification algorithms if you choose to expand the project beyond basic matching.Streamlit: An open-source app framework for Machine Learning and Data Science teams. It allows for quick creation of beautiful, interactive web applications directly from Python scripts, making it perfect for demonstrating this project's capabilities.
- 🔩 Step-by-Step Build:Collect Sample Resumes:Preparation: Gather a diverse set of 10-20 sample resumes. These should ideally be in PDF format and represent various levels of experience (e.g., junior, mid-level, senior) and possibly different industries.Diversity is Key: Include resumes with different layouts, font styles, and sections to stress-test your parsing and extraction logic. This will help you identify edge cases and make your scanner more robust.Resume Parsing (Text Extraction from PDFs):Objective: Convert the binary PDF file into raw, readable text.Tooling: Use
PyPDF2(simpler for straightforward PDFs) orpdfminer.six(more powerful for complex layouts and extracting positional information).Process: Iterate through each page of the PDF, extract its text content.Initial Cleaning: Immediately after extraction, perform basic cleaning to remove extraneous characters, excessive whitespace, and normalize line breaks (\nto single space or remove). PDF extraction can often introduce messy formatting.Text Preprocessing:Standardization:Convert to lowercase: Crucial for consistent matching and analysis, ensuring "Python" and "python" are treated the same.Remove stopwords: Eliminate common words (e.g., "the", "a", "is") that don't add significant value to skill or keyword matching.Remove special characters and numbers: Strip punctuation, symbols, and numerical digits, unless specific numbers (e.g., years of experience) are intended features.Tokenization (using SpaCy): Break the cleaned text into individual words or phrases (tokens). SpaCy's tokenizer is highly efficient and intelligent.Advanced: Consider Lemmatization (using SpaCy or NLTK's WordNetLemmatizer) to reduce words to their base form (e.g., "running," "ran," "runs" become "run"), further improving consistency for skill matching.Keyword & Skill Extraction:Predefined Skills List: Create or obtain a comprehensive list of relevant skills. This can be a simple Python list, a JSON file, or even loaded from a CSV. Categorize skills (e.g., programming languages, frameworks, soft skills).Rule-Based (Regex): Use regular expressions to identify patterns like email addresses, phone numbers, or specific skill formats (e.g., "Java Developer," "SQL").Named Entity Recognition (NER) with SpaCy:Load a pre-trained SpaCy model (e.g.,en_core_web_sm,en_core_web_lg).Process the cleaned resume text with the SpaCy model.Extract entities tagged asPERSON,ORG(for previous employers),GPE(for locations), and potentially extend SpaCy's pipeline or use rule-based matching to extract specificSKILLentities. You might need to build a custom component for highly accurate skill recognition.Job Match Scoring:Input: Obtain a job description (JD) as a separate input from the user.Preprocessing JD: Apply the exact same text preprocessing steps to the job description as you did for the resumes.TF-IDF Vectorization: Create aTfidfVectorizerand fit it on a combined corpus of all resumes and the job description (or fit it on a very large, diverse text corpus of professional documents). Then, transform both the processed resume text and the job description text into TF-IDF vectors.Cosine Similarity Calculation: Compute the cosine similarity between the TF-IDF vector of each resume and the TF-IDF vector of the job description. The resulting score, typically a floating-point number between 0 and 1, represents how semantically similar the resume is to the job description.Score as Percentage: Convert the cosine similarity score to a percentage (e.g., score * 100). This provides an intuitive "match percentage."User Interface with Streamlit:Interactive Upload: Design a Streamlit app where users can easily upload a PDF resume file and paste (or upload) a job description text.Display Parsed Content: Show the extracted raw text and key entities (name, contact info, skills) from the resume.Job Match Score Display: Clearly present the calculated job match percentage.Actionable Feedback (Optional but Recommended):Missing Keywords: Identify and list keywords from the job description that are present in the job description but not found in the resume.Strong Skills: Highlight skills from the resume that are also present in the job description.Overall Recommendation: Provide a simple "Good Match," "Moderate Match," or "Low Match" based on the percentage score.Layout: Use Streamlit's columns and containers to create a clean, responsive layout.Bonus Features (Advanced Extensions):Resume Ranking for Multiple Uploads: Extend the UI to allow uploading multiple resumes simultaneously. Calculate the match score for each against a single job description and display them in a ranked list, just like an ATS would.Integration with LinkedIn/Job Board Scraping APIs: Instead of manual input, integrate with a (legally and ethically sourced) API to pull job descriptions directly from popular job boards or even anonymized LinkedIn profiles. (Note: Be mindful of terms of service and ethical scraping practices.)ChatGPT-Powered Resume Improvement Tips: After analyzing the resume and job description, use a large language model (LLM) like Gemini's API to generate personalized suggestions for improving the resume's alignment with the job description. For example, if the resume is missing specific industry buzzwords from the JD, the LLM could suggest adding them. This would require integrating an LLM API call within your Streamlit app.
Project 3: Smart Resume Scanner with NLP + Streamlit Codes:
🔗 View Project Code on GitHub
4. 🤖 Machine Learning Chatbot using Rasa or ChatterBot

- 🔍 Overview: Building Intelligent Dialogue Systems for Modern InteractionsIn a world increasingly driven by digital convenience and instant communication, AI-powered conversational chatbots have evolved from rudimentary Q&A systems into core components of modern business operations. In 2025, they are no longer just "nice-to-haves" but essential for delivering personalized experiences across diverse sectors, including customer support, HR, e-commerce, healthcare, and education. They streamline operations, provide 24/7 assistance, and significantly enhance user engagement.This project offers a deep dive into the fascinating field of conversational AI, empowering you to build a sophisticated chatbot that not only understands user intent and extracts critical information but also remembers context across multiple turns of dialogue and responds intelligently. You'll gain hands-on experience in designing intuitive conversational flows, training advanced intent classifiers using Natural Language Understanding (NLU) techniques, and deploying a chatbot capable of holding natural, real-time dialogues. Crucially, this project focuses on developing the core AI logic without relying on OpenAI or external proprietary APIs, emphasizing the fundamental principles and open-source tooling you can leverage independently. This makes it perfect for substantial portfolio work, robust college projects, and direct real-world deployment within business websites or mobile applications, giving you full control over the AI.
- 🧠 Skills You’ll Learn:Intent Classification and Entity Extraction: Master the art of recognizing a user's underlying goal (intent) and pulling out key pieces of information (entities) from their natural language input.Conversational Flow and Dialogue Management: Design multi-turn conversations, manage the state of the dialogue, and implement strategies for handling unexpected inputs or unclear user intentions (fallback handling).NLU/NLP Pipelines with Training Data: Understand how to build and optimize end-to-end Natural Language Understanding (NLU) and Natural Language Processing (NLP) pipelines, from data collection and annotation to model training and evaluation.Building and Deploying Rule-Based or ML-Based Chatbots: Gain practical experience in selecting and implementing appropriate chatbot architectures, whether relying on explicit rules for simpler interactions or machine learning for more dynamic and adaptable conversations.Integration with Web Interfaces: Connect your conversational AI backend to a user-facing web interface, demonstrating how to make your chatbot accessible to end-users.
- 🧪 Algorithms Used:Logistic Regression / Decision Trees (or similar classifiers within Rasa's NLU pipeline): These supervised machine learning algorithms are commonly used in Rasa's NLU component for intent classification, where the model learns to categorize user utterances into predefined intents based on training examples.Sequence Matching (in ChatterBot): ChatterBot often uses a more rule-based or statistical approach that involves finding the closest matching response from its corpus based on the similarity of the input statement to previous learned statements.Rule-based Fallback and Confidence Scoring: Implement logic to handle situations where the chatbot doesn't confidently understand the user's input, providing generic responses or asking for clarification. Confidence scores from the NLU model help trigger these fallbacks.
- 🛠️ Tech Stack:Python: The primary programming language for all components of the chatbot.Rasa Open Source (Recommended): A powerful, open-source framework for building contextual AI assistants. It provides comprehensive tools for NLU, dialogue management (stories, rules, forms), and action execution, making it suitable for complex, production-ready chatbots.ChatterBot (Alternative): A simpler, lightweight library for building chatbots that learn to respond based on collections of user conversations. It's often quicker to set up for basic Q&A bots and provides a good starting point for understanding conversational AI fundamentals.NLTK / SpaCy (for NLU preprocessing): Essential NLP libraries used for foundational text processing tasks within the chatbot's NLU pipeline, such as tokenization, lemmatization, and potentially part-of-speech tagging for more advanced entity extraction.Flask (for Frontend or Integration): A lightweight Python web framework used to create a simple web interface for your chatbot, allowing users to interact with it via a browser, or to serve as a REST API endpoint for integration with other UI frameworks.
- 🔩 Step-by-Step Build:Choose a Chatbot Framework:Rasa Open Source:When to Use: Ideal for building complex, contextual, and production-ready conversational AI. It excels at handling multi-turn conversations, managing dialogue state, and integrating custom business logic. Provides robust NLU and dialogue management.Installation:
pip install rasa(ensure you havePython 3.8+andNode.jsinstalled for Rasa X/UI components if you explore them later).ChatterBot:When to Use: Suitable for simpler Q&A bots, quick prototypes, or scenarios where you want a "plug-and-play" model that learns from a given corpus of conversations. It's less focused on strict conversational flow management.Installation:pip install chatterbot chatterbot_corpusInitial Setup: Userasa init(for Rasa) to create a starter project structure with example files, or simply create a Python script and import ChatterBot.Design Conversational Intents & Entities:Intent Definition: Identify the various goals or purposes a user might have when interacting with your chatbot (e.g.,greet,farewell,ask_time,order_pizza,check_status).Training Examples (Utterances): For each intent, write 5-10 diverse example phrases or sentences that users might say. Include variations, synonyms, and different phrasing to help the NLU model generalize.Entity Extraction: Within these examples, identify and label key pieces of information (entities) that your chatbot needs to extract. Forask_time, "New York" could be acityentity. Forbook_appointment, "tomorrow" could be adateentity, and "dentist" could be aserviceentity.Create Training Data Files:Rasa:data/nlu.yml: Contains your user examples, intents, and entities. This trains the NLU model to understand user messages.domain.yml: Defines the universe of your assistant: all intents, entities, responses (what the bot says), slots (memory variables), and custom actions.data/stories.yml(covered in next step): Defines example conversations.data/rules.yml(for fixed responses or simple fallback).ChatterBot: Typically uses a list of statements (conversational pairs) or can be trained on a pre-existing corpus. Simpler setup without explicit intent/entity files.Train the Model:Rasa:Use the Rasa CLI command:rasa train. This command will train both your NLU model (for intent classification and entity extraction) and your dialogue management model (for determining the next action based on conversation history).Evaluation during Training: Rasa provides metrics during training. Monitor thelossandaccuracyfor the NLU model and thef1-scorefor the dialogue model. Adjust training data or model configuration (inconfig.yml) as needed.Testing: After training, runrasa test nluto evaluate NLU performance on a separate test set, andrasa test coreto evaluate how well your stories are followed.ChatterBot:Instantiate your chatbot and use itstrainerobject to train it, typically with a list of statements or a corpus. The training process involves building an internal knowledge graph to find the best response.Define Conversation Flow (Stories) - Rasa-specific for complex dialogue:Rules (data/rules.yml): For very simple, fixed behaviors (e.g., always respond withutter_denyif intent isdeny).Fallback Intent: Implement a fallback mechanism in yourdomain.ymlandrules.ymlorstories.ymlto gracefully handle cases where the NLU model is uncertain about the user's intent. This prevents the bot from giving irrelevant responses. Example: whennlu_fallbackis triggered,action: utter_did_not_understand.Forms: For collecting multiple pieces of information from the user (e.g., booking an appointment requires date, time, service). Rasa Forms simplify this process by defining required slots and guiding the conversation until all information is collected.Deploy the Chatbot:Local Command-Line Interface (Rasa):Run the Rasa server:rasa run(starts the action server if you have custom actions).Interact via shell:rasa shell(allows you to chat with your bot directly in the terminal).Web Integration (Flask + REST API):Your trained Rasa model can expose a REST API endpoint.Build a simple Flask application that serves an HTML page with a chat interface (using basic HTML, CSS, and JavaScript).The JavaScript code on the frontend will send user messages to the Rasa API endpoint (e.g.,/webhooks/rest/webhook) and display the bot's responses.Benefit: This creates a demonstrable web application that showcases your chatbot.Bonus Features (Advanced Customization):Add Custom Actions: Extend your chatbot's capabilities by writing custom Python code (inactions.pyfor Rasa). These actions can perform more complex logic, such as:Connecting to a database to fetch or store information.Performing calculations (e.g., calculating time differences forask_time).Interacting with internal APIs (e.g., querying a product catalog, checking inventory).Integrate with Messaging Channels (e.g., WhatsApp, Telegram with Twilio): Explore how to connect your Rasa chatbot to popular messaging platforms using connectors (e.g., Twilio for WhatsApp/SMS, Telegram API). This involves setting up webhooks and configuring your Rasacredentials.yml.Add a Database Connection for Storing User Interactions:Purpose: Persist user conversations for analytics, debugging, and future model improvements.Implementation: Use a lightweight database (e.g., SQLite, PostgreSQL) and connect to it from your custom actions to log user inputs, bot responses, and extracted entities. This data can be invaluable for understanding user behavior and identifying areas for chatbot enhancement.
Stories (data/stories.yml): Define example multi-turn conversations that your chatbot should be able to handle. Each story maps a sequence of user intents and extracted entities to corresponding bot actions (e.g., utter_greet, action_ask_time).
- story: happy path greeting
steps:
- intent: greet
- action: utter_greet
- intent: mood_great
- action: utter_happy
Example for Rasa (in nlu.yml):
- intent: greet
examples: |
- hey
- hello
- hi
- intent: ask_time
examples: |
- what time is it
- current time
- tell me the time in [London](city)
- time in [Tokyo](city) now
Project 4: Machine Learning Chatbot using Rasa or ChatterBot Codes:
🔗 View Project Code on GitHub5. 📈 Sales Forecasting with Linear Regression
- 🔍 Overview: Driving Business Strategy with Predictive Sales InsightsIn the competitive and rapidly evolving business landscape of 2025, the ability to accurately predict future sales is no longer a luxury but a fundamental necessity. For industries spanning retail, manufacturing, e-commerce, SaaS, and even services, precise sales forecasts directly impact critical business decisions – from optimizing inventory levels and managing supply chains efficiently to planning marketing campaigns, allocating resources, and setting strategic growth targets. Inaccurate forecasts can lead to overstocking (tying up capital) or understocking (missing sales opportunities).This project equips you with the essential skills to build a robust data-driven sales forecasting model using historical sales data. You will embark on a complete machine learning pipeline, starting with ingesting and meticulously cleaning time-stamped datasets. You'll then learn to visualize inherent trends and seasonal patterns, train powerful regression models, and ultimately predict future revenue with quantifiable accuracy. This project provides a tangible solution to a real-world business problem that every aspiring data analyst or junior ML engineer should master, making it an invaluable addition to your resume, suitable for creating interactive dashboards, and ready for deployment in business operations.
- 🧠 Skills You’ll Learn:Time-series data preparation and manipulation: Master techniques for handling sequential data, including parsing dates, re-sampling, dealing with missing values, and structuring data for time-series specific models. You'll learn to identify and handle trends, seasonality, and cyclical components.Regression modeling (linear and polynomial): Understand the application of fundamental regression algorithms for predicting continuous values. You'll learn how to choose appropriate models based on data patterns and interpret their coefficients.Feature Engineering for Time Series: Develop the ability to extract meaningful features from date/time information and create lagged variables that capture the historical influence on future values, significantly improving model performance.Model performance evaluation for regression: Beyond simple accuracy, you'll learn to use and interpret key metrics like MAE, RMSE, and R² score, understanding their implications for business decision-making. You'll also learn to visualize prediction errors (residuals) to diagnose model weaknesses.Forecasting visualization with trend lines: Create compelling and informative plots using
MatplotlibandSeabornto display historical sales alongside predicted future trends, making insights easily digestible for stakeholders. - 🧪 Algorithms Used:Linear Regression: A foundational supervised learning algorithm that models the relationship between a dependent variable (sales) and one or more independent variables (time, features) by fitting a linear equation to the observed data. It provides a simple, interpretable baseline.Polynomial Regression (optional for non-linear trends): An extension of linear regression that models the relationship as an nth-degree polynomial. This is crucial when the relationship between time and sales is not strictly linear, allowing the model to capture curvilinear patterns and more complex trends (e.g., accelerating or decelerating growth).Evaluation Metrics:MAE (Mean Absolute Error): The average of the absolute differences between predictions and actual values. It's straightforward to interpret and less sensitive to outliers than MSE/RMSE.RMSE (Root Mean Squared Error): The square root of the average of squared errors. It gives a relatively high weight to large errors, making it useful when significant errors are particularly undesirable. It's in the same units as the target variable.R² Score (Coefficient of Determination): Represents the proportion of the variance in the dependent variable that is predictable from the independent variables. A higher R² indicates a better fit; for example, an R² of 0.8 means 80% of the variance in sales can be explained by your model.
- 🛠️ Tech Stack:Python: The core programming language for data manipulation, model building, and visualization.Pandas: The go-to library for data manipulation and analysis, particularly powerful for handling time-series dataframes (e.g.,
pd.to_datetime,resample,groupby).NumPy: Essential for numerical operations and array manipulation, which is fundamental for preparing data for Scikit-learn and other numerical computations.Scikit-learn: A comprehensive machine learning library in Python providing efficient implementations of various algorithms, includingLinearRegression,PolynomialFeatures, and a wide array of evaluation metrics (mean_absolute_error,mean_squared_error,r2_score).Matplotlib / Seaborn: Powerful libraries for creating static, interactive, and aesthetically pleasing data visualizations.Matplotlibforms the base, whileSeabornbuilds on it to offer higher-level functions for statistical graphics, making trend and forecast plots intuitive. - 🔩 Step-by-Step Build:Get the Dataset:Source: Utilize a public dataset with historical sales data. Excellent choices include:Walmart Sales Forecasting (Kaggle): Often includes weekly sales, store and department IDs, and macroeconomic factors.Superstore Sales Dataset: A common business analytics dataset with sales, profit, order date, categories, etc.Generic Monthly/Daily Sales CSV: You can even create a simple CSV with a
Datecolumn and aSales(orRevenue) column.Columns: Ensure your dataset has at least aDateorTimestampcolumn and a numericalSales(orRevenue) column. Bonus if it includes other relevant features likeCategory,Product ID,Promotional Flag,Holiday Indicator, orStore ID.Data Preprocessing:Date Conversion: The first critical step for time series is to convert theDatecolumn to Python'sdatetimeformat usingpd.to_datetime(). Set this as the DataFrame's index for easier time-series operations.Handle Missing or Zero Values: Sales data might have gaps. Employ techniques like:Interpolation (.interpolate()): Fill missing values based on surrounding data points (e.g., linear interpolation).Forward-fill (.ffill()): Propagate the last valid observation forward.Backward-fill (.bfill()): Propagate the next valid observation backward.Zero handling: Decide if zero sales mean no sales or missing data; treat accordingly.Group Sales by Week/Month for Trend Smoothing: Raw daily sales can be noisy. Aggregate data to a coarser granularity (e.g., weekly or monthly sums using.resample('W').sum()or.resample('M').sum()) to reveal clearer underlying trends and seasonality. This also reduces the data size and computational load.Feature Engineering:Extract Time-Based Features: Create new columns from yourdatetimeindex that can capture cyclical patterns and trends:month:df.index.month(1-12)quarter:df.index.quarter(1-4)year:df.index.yeardayofweek:df.index.dayofweek(0-6)dayofyear:df.index.dayofyear(1-366)weekofyear:df.index.isocalendar().weekis_month_start,is_month_end,is_quarter_start,is_quarter_end,is_year_start,is_year_end(boolean flags for key periods).Create Lag Features: These are past values of the target variable that become input features. For example,sales_lag_1would be sales from the previous period. This helps the model learn from recent history.df['sales_lag_1'] = df['Sales'].shift(1)Rolling Averages/Statistics: Create features that represent the average sales over a recent window (e.g., 7-day rolling average) to smooth out noise and capture short-term trends.df['rolling_mean_7'] = df['Sales'].rolling(window=7).mean()One-Hot Encoding: Convert categorical features (likemonthordayofweek) into numerical format suitable for regression models if they aren't already treated as continuous.Train/Test Split:Time-Series Split: Unlike random splitting, time series data requires a sequential split to preserve the temporal order. Use earlier data for training and later data for testing. This simulates predicting truly unseen future events.split_point = int(len(df) * 0.8)train_data = df.iloc[:split_point]test_data = df.iloc[split_point:]Normalization (if necessary): For certain models (like LSTMs or models sensitive to feature scales), normalize your sales and engineered features usingMinMaxScalerorStandardScaler. Remember to fit the scaler only on the training data and then transform both train and test sets.Model Training:Fit a Linear Regression Model: Train aLinearRegressionmodel fromsklearn.linear_modelusing your prepared features (X_train) and sales (y_train). This will establish a baseline prediction.model_linear = LinearRegression()model_linear.fit(X_train_features, y_train_sales)Optionally Train Polynomial Regression for Complex Patterns:UsePolynomialFeaturesfromsklearn.preprocessingto create polynomial combinations of your original features. This transforms the feature space, allowingLinearRegressionto fit non-linear relationships.Experiment with different degrees (e.g.,degree=2ordegree=3) to see if it improves the fit on non-linear trends.poly = PolynomialFeatures(degree=2)X_train_poly = poly.fit_transform(X_train_features)model_poly = LinearRegression().fit(X_train_poly, y_train_sales)Hyperparameter Tuning (Advanced): For more sophisticated models or to fine-tunePolynomialFeaturesdegree, considerGridSearchCVorRandomizedSearchCVfor hyperparameter optimization.Model Evaluation:Predictions on Test Set: Generate predictions on yourX_testdata using your trained models.predictions_linear = model_linear.predict(X_test_features)predictions_poly = model_poly.predict(X_test_poly)Calculate Metrics: Compute MAE, RMSE, and R² score for both Linear and Polynomial Regression models on the test set to quantitatively compare their performance.from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_scoremae = mean_absolute_error(y_test_sales, predictions)rmse = np.sqrt(mean_squared_error(y_test_sales, predictions))r2 = r2_score(y_test_sales, predictions)Plot Actual vs. Predicted Sales: UseMatplotlibandSeabornto visualize how well your model's predictions align with the actual sales on the test set.Plot bothy_test_salesandpredictionson the same graph, using the test data's dates on the x-axis.Visualize residuals (the differences between actual and predicted values) to check for patterns, which can indicate if your model is consistently under- or over-predicting.Forecast Future Sales:Extend the Timeline: Create a DataFrame with future dates (e.g., next 3, 6, or 12 months) beyond your historical data.Generate Future Features: Apply the same feature engineering steps (month, quarter, year, lag features, rolling averages) to these future dates. For lag features, you'll need to use the last known actual sales from your historical data and then iteratively use your model's own predictions for subsequent lags.Predict Future Sales: Use your chosen best-performing model topredict()sales for these future dates based on their engineered features.Visualize Forecast: Extend your actual vs. predicted plot to include the forecasted future sales, clearly showing the historical trend and the projected path. This provides a clear business insight.Bonus Features (Advanced Deployment & Utility):Add Product-Level/Category-Level Sales Forecasting: Instead of just total sales, expand your project to allow users to select a specific product category or individual product, and then generate forecasts for that specific segment. This requires iterating through product categories and training separate models or building a more complex hierarchical model.Deploy as a Streamlit App for Dashboard-Based Predictions: Transform your forecasting script into an interactive Streamlit web application. Users could upload their own sales data (CSV), select parameters (e.g., forecast horizon), and instantly see the generated forecast plot and key metrics within a dashboard. This makes the project highly presentable and user-friendly.Export Forecasts to CSV/Excel for Stakeholders: Implement functionality to allow users to download the generated future sales forecasts as a CSV or Excel file. This provides a tangible output that business stakeholders can use for their planning and reporting.Incorporate External Factors: For more advanced forecasting, you could integrate external data like economic indicators (GDP, inflation), promotional spend, competitor activities, or even weather data if relevant to the product.
Project 5: Sales Forecasting with Linear Regression Codes:
🔗 View Project Code on GitHub
🚀 Ready to transform your curiosity for data into a career-defining edge?
At Huebits, we don’t just teach Data Science—we empower you to analyze, predict, and lead with hands-on experience, real-world capstone projects, and cutting-edge tools like Python, Scikit-learn, Pandas, TensorFlow, Power BI, and FastAPI.
🧠 Whether you're a student, analyst, or future AI leader, our Industry-Ready DS, AI & ML Program is crafted to make you future-proof. Master machine learning, data analytics, AI-driven solutions, and full-stack deployment—all in one immersive, career-launching journey.
🎓 Next Cohort starts soon!
🔗 Join Now to claim your seat and take the first step into India’s booming ₹800 billion+ AI & Analytics ecosystem.
6. 🧬 Disease Prediction System using Machine Learning

- 🔍 Overview: Leveraging AI for Early Disease Detection in HealthcareIn the critical domain of healthcare, early and accurate disease prediction holds the potential to save lives, reduce healthcare costs, and significantly improve patient outcomes. This project guides you through the process of building an intelligent disease prediction system that acts as a powerful diagnostic aid. By taking various patient symptoms and clinical parameters as input, your machine learning model will predict the likelihood of specific conditions, such as diabetes, heart disease, or kidney failure.You will gain invaluable experience working with sensitive health datasets, which comes with its own unique challenges related to data privacy, ethical considerations, and data quality. This project focuses on applying core Machine Learning classification techniques to medical data, building interactive predictive forms, and ultimately creating a real-time diagnostic tool. Such systems are highly sought after by health tech startups, can be integrated into mobile health applications, or serve as decision-support tools for diagnostic platforms, empowering both patients and healthcare providers. The emphasis is on building models that are not only accurate but also interpretable, crucial for trust and adoption in clinical settings.
- 🧠 Skills You’ll Learn:Medical Dataset Preprocessing: Master the intricacies of cleaning, transforming, and preparing clinical data, including handling sensitive patient information, managing imbalanced datasets (where healthy cases far outnumber disease cases), and addressing domain-specific data anomalies.Binary and Multi-Class Classification: Understand the theoretical foundations and practical application of supervised learning algorithms to categorize patients into disease/non-disease (binary) or multiple disease categories (multi-class).Building Interactive Forms with Streamlit/Tkinter: Develop practical skills in creating user-friendly graphical interfaces that allow easy input of patient data and clear display of predictive outputs, making your model accessible.Evaluating Models for Precision in High-Risk Scenarios: Learn to critically assess model performance using specialized metrics vital for healthcare, where the cost of a false negative (missing a disease) can be far greater than a false positive (incorrectly flagging a healthy individual). This involves understanding trade-offs between different error types.Basic Understanding of Medical Data Privacy (e.g., HIPAA principles): While not full compliance, this project implicitly encourages awareness of handling sensitive patient information responsibly.
- 🧪 Algorithms Used:Logistic Regression: A fundamental linear classifier that estimates the probability of a binary outcome. It's often used as a baseline and provides interpretable coefficients indicating feature importance.Random Forest Classifier: An ensemble learning method that builds multiple decision trees and merges their predictions. It's highly robust, handles non-linear relationships well, and provides feature importance scores.Support Vector Machine (SVM): A powerful algorithm for classification that finds an optimal hyperplane to separate data points into classes. Effective in high-dimensional spaces and for complex decision boundaries.K-Nearest Neighbors (KNN): A simple, non-parametric, instance-based learning algorithm that classifies a new data point based on the majority class of its 'k' nearest neighbors in the feature space.Evaluation Metrics (Crucial in Healthcare):Confusion Matrix: A table summarizing the performance of a classification model, visually showing True Positives, True Negatives, False Positives, and False Negatives. It's the foundation for other metrics.Precision: (True Positives / (True Positives + False Positives)). The proportion of positive identifications that were actually correct. High precision is important to avoid unnecessary stress or further tests on healthy individuals.Recall (Sensitivity): (True Positives / (True Positives + False Negatives)). The proportion of actual positive cases that were correctly identified. In disease prediction, often the most critical metric, as a high recall minimizes the risk of missing a disease (false negatives).F1-Score: The harmonic mean of Precision and Recall. Provides a single score that balances both metrics, particularly useful for imbalanced datasets.ROC-AUC (Receiver Operating Characteristic - Area Under the Curve): Measures the ability of a classifier to distinguish between classes. A higher AUC indicates better discriminatory power across various classification thresholds. It's robust to imbalanced datasets.
- 🛠️ Tech Stack:Python: The primary programming language.Pandas: For efficient data loading, manipulation, and cleaning of tabular medical datasets.NumPy: Essential for numerical operations and array manipulation, which is fundamental for mathematical computations within ML models.Scikit-learn: The cornerstone library for implementing all the machine learning algorithms, preprocessing techniques (scaling, encoding), and evaluation metrics.Streamlit or Tkinter (for UI):Streamlit (Recommended): A modern, efficient way to build interactive web applications purely in Python, perfect for creating dynamic input forms and visualizing results in a browser.Tkinter: Python's standard GUI (Graphical User Interface) toolkit, suitable for creating desktop applications if a web-based UI isn't preferred.
- 🔩 Step-by-Step Build:Download Medical Dataset:Sources: Utilize publicly available datasets from platforms like Kaggle, which are specifically designed for educational and research purposes:Diabetes Dataset: Often includes features like Glucose, Blood Pressure, BMI, Age, and the target variable indicating diabetes presence.Heart Disease UCI Dataset: Contains features such as age, sex, cholesterol, blood pressure, and a target variable indicating heart disease.Understanding Data: Before diving into code, spend time understanding the dataset's features (columns), their units, data types, and potential meaning in a medical context. Identify the target variable (the disease outcome).Data Cleaning:Handle Missing Values: Medical datasets often have missing entries. Strategically impute (fill in) these values using techniques like:Mean/Median Imputation: Replacing missing values with the mean or median of the column.Mode Imputation: For categorical features.More Advanced: K-NN Imputation (imputing based on similar rows), or even predictive imputation using other features. Avoid simply dropping rows/columns unless absolutely necessary, as medical data can be scarce.Normalize/Standardize Features: Ensure all numerical features are on a similar scale to prevent features with larger values from dominating the learning process.
MinMaxScaler: Scales features to a range [0, 1].StandardScaler: Standardizes features by removing the mean and scaling to unit variance. Choose based on model requirements and data distribution.Remove Outliers (if needed): Outliers can skew model training. Identify and handle them using:Z-score Method: Flags data points that are a certain number of standard deviations away from the mean.IQR (Interquartile Range) Method: Identifies outliers as points falling outside 1.5 times the IQR below Q1 or above Q3.Caution: In healthcare, outliers might represent rare but significant cases. Domain expertise is crucial to decide whether to remove, transform, or keep them.Feature Engineering:Encode Categorical Variables: Convert non-numerical (categorical) features (e.g., 'Gender' - 'Male'/'Female', 'Chest Pain Type' - 'Typical Angina', 'Atypical Angina') into a numerical format that machine learning models can understand.One-Hot Encoding (pd.get_dummies()orOneHotEncoderfromsklearn.preprocessing): Creates new binary columns for each category.Label Encoding (LabelEncoder): Assigns a unique integer to each category (use carefully, as it might imply ordinality).Create Interaction Terms (Optional): Combine existing features to create new ones that might capture more complex relationships (e.g.,Age * BMI).Polynomial Features (Optional): If relationships are non-linear, generate polynomial combinations of existing features (similar to the sales forecasting project).Model Selection & Training:Train Multiple Models: It's best practice to try a variety of classification algorithms (Logistic Regression, Random Forest, SVM, KNN) to see which performs best on your specific dataset.Train-Test Split: Divide your data into training and testing sets (e.g., 70-80% for training).Hyperparameter Tuning withGridSearchCVorRandomizedSearchCV:Purpose: Fine-tune the internal parameters (hyperparameters) of each chosen algorithm to optimize its performance.GridSearchCVsystematically explores all specified combinations of hyperparameters.RandomizedSearchCVsamples a fixed number of parameter settings from a distribution.Benefit: This significantly improves model performance and generalization capability.Example (for Random Forest): Tunen_estimators(number of trees),max_depth,min_samples_leaf, etc.Model Evaluation (Healthcare Specific):Predict on Test Data: Generate predictions (predict()) and prediction probabilities (predict_proba()) on the unseen test set.Confusion Matrix: Generate and visualize the confusion matrix. This provides a detailed breakdown of correct and incorrect classifications.Prioritize Recall over Precision (Often):In disease prediction, False Negatives (missing a disease) are often more critical and carry a higher cost (patient outcome, public health risk) than False Positives (misdiagnosis leading to further tests). Therefore, models with higher Recall are frequently preferred, even if it means a slightly lower precision.Evaluate Precision, Recall, and F1-Score for each class.ROC-AUC Score: Calculate the ROC-AUC score. A higher AUC indicates a better model in terms of distinguishing between sick and healthy patients. Plot the ROC curve to visualize this trade-off across different thresholds.Cross-Validation: Use techniques like K-Fold Cross-Validation during training (often integrated intoGridSearchCV) to get a more robust estimate of model performance and reduce reliance on a single train-test split.Choose the Best Model: Select the model that performs optimally based on your chosen evaluation strategy (e.g., highest F1-score or a good balance of precision and recall, leaning towards recall for high-stakes medical predictions).Build the UI App (Streamlit/Tkinter):Streamlit App (Web-based):Create a clean and intuitive web form usingst.sidebarfor inputs andst.mainfor displaying results.Add input fields for each patient symptom/parameter (e.g., age, blood pressure, glucose level, BMI, etc.). Use sliders, text inputs, radio buttons, or dropdowns as appropriate for each feature.On submission, collect the input, preprocess it (using the same scaler and encoder fitted during training), pass it to the loaded best-performing model for prediction.Display Predictions: Clearly show the predicted outcome (e.g., "High Risk of Diabetes," "Low Risk of Heart Disease") and, importantly, the prediction probabilities (e.g., "75% likelihood").Optional Visualizations: Include simple graphs (e.g., bar chart of input values vs. average for disease group) or personalized health advice based on the prediction (e.g., "Consult a doctor," "Maintain a healthy diet").Tkinter App (Desktop-based): If you prefer a desktop application, use Tkinter to create windows, labels, entry fields, and buttons for input and output display.Bonus Features (Enhance Clinical Utility & Scalability):Predict Multiple Diseases using Separate Models: Extend the system to incorporate different medical datasets and train individual models for various diseases (e.g., one model for diabetes, another for heart disease). The UI could then allow users to select which disease they want to predict.Integrate with Wearable or IoT Health Data: Explore how to connect your system to real-time health data streams from wearables (e.g., smartwatches measuring heart rate, sleep patterns) or IoT medical devices. This would involve APIs for data ingestion and potentially real-time inference.Add PDF Report Generator with Prediction Summary: Implement functionality to generate a downloadable PDF report summarizing the patient's input, the model's prediction, key influencing factors (e.g., feature importance from Random Forest), and recommended next steps. This adds a professional touch suitable for clinical mock-ups.Explainable AI (XAI) Integration: For critical healthcare applications, understanding why a model made a particular prediction is as important as the prediction itself. Integrate libraries likeSHAPorLIMEto generate local explanations for individual predictions, showing which input features contributed most to the outcome.
Project 6: Disease Prediction System using Machine Learning Codes:
🔗 View Project Code on GitHub7. 😷 Face Mask Detection using Computer Vision & Deep Learning

- 🔍 Overview: Real-time Public Health and Safety Monitoring with Computer VisionEven in a post-pandemic world, the ability to rapidly and accurately detect face masks remains an incredibly critical application of computer vision. This technology is vital for ensuring public health compliance in high-density areas, enhancing smart surveillance systems, and maintaining industrial safety protocols where PPE (Personal Protective Equipment) is mandatory. This project provides you with a hands-on opportunity to build a powerful Face Mask Detection system by training a Convolutional Neural Network (CNN).What makes this project particularly impactful is its real-time capability: you will learn to deploy your trained model to detect whether individuals are wearing masks directly through your webcam feed. This makes it a highly practical, high-impact solution perfect for various deployment scenarios, including airports, hospitals, schools, retail environments, or industrial factories, where automated monitoring can significantly bolster safety and compliance efforts. You'll gain a deep understanding of the entire computer vision pipeline, from data preparation and model architecture design (either from scratch or leveraging transfer learning) to real-time video processing and visual overlay techniques using OpenCV.
- 🧠 Skills You’ll Learn:Image Classification: Master the core concept of categorizing images into predefined classes (e.g., 'with_mask', 'without_mask').CNN Architecture (or MobileNetV2 for Transfer Learning): Gain an in-depth understanding of Convolutional Neural Networks, including how convolutional layers extract features, pooling layers reduce dimensionality, and dense layers classify. Alternatively, learn to leverage the power of transfer learning by fine-tuning a pre-trained, lightweight CNN like MobileNetV2, which is highly effective for image-based tasks and often faster to train.Real-time Video Processing: Develop skills in capturing live video streams from a webcam, processing frames sequentially, and applying machine learning predictions in real-time.Computer Vision Deployment using OpenCV: Learn to integrate your trained deep learning model into a practical computer vision application using the versatile OpenCV library for tasks like face detection, image manipulation, and drawing bounding boxes/labels.Data Augmentation for Images: Understand how to artificially expand your training dataset to improve model generalization and robustness, especially when dealing with limited image data.
- 🧪 Algorithms Used:CNN (Convolutional Neural Network): The primary deep learning architecture for image analysis. You can choose to build a custom CNN from scratch (e.g., using
Conv2D,MaxPooling2D,Flatten,Denselayers) or leverage the power of a pre-trained network.MobileNetV2 (for Transfer Learning): A highly efficient and lightweight pre-trained CNN architecture developed by Google, optimized for mobile and embedded vision applications. Using it for transfer learning involves leveraging its pre-learned features and fine-tuning the top layers for your specific mask detection task.Haar Cascade or Dlib for Face Detection:Haar Cascade Classifiers: A machine learning-based approach (using cascades of boosted classifiers working on Haar-like features) for object detection. It's fast and effective for detecting faces in real-time.Dlib (Optional): A modern C++ toolkit with Python bindings, offering more robust and accurate face detection (e.g., using HOG + SVM) compared to Haar Cascades, though sometimes slower.Softmax Activation for Binary Classification: For the output layer of your CNN,softmax(orsigmoidfor binary classification if 1 output unit) is used to output probabilities for each class ('with_mask', 'without_mask'). In binary classification,sigmoidis common for a single output neuron, providing a probability for one class. - 🛠️ Tech Stack:Python: The foundational programming language for the entire project.TensorFlow / Keras: The leading open-source machine learning framework for building and training deep learning models. Keras provides a high-level, user-friendly API for rapid prototyping.OpenCV (Open Source Computer Vision Library): An essential library for image and video processing tasks, including capturing webcam feeds, manipulating image frames, drawing annotations (bounding boxes, text), and loading pre-trained face detectors.NumPy: Crucial for efficient numerical operations, especially for handling image data as arrays and performing mathematical computations.Matplotlib: For visualizing training history (accuracy, loss plots) and displaying processed image frames.Streamlit (Optional for UI): A fantastic tool for quickly building interactive web applications for your computer vision project, allowing users to upload images or use their webcam within a browser-based interface.
- 🔩 Step-by-Step Build:Collect or Download Dataset:Source: Obtain a suitable public dataset containing images of people with and without face masks. A highly recommended source is the Face Mask Dataset on Kaggle. These datasets are typically well-structured and labeled.Organization: Ensure your dataset is organized into two distinct folders (e.g.,
/dataset/with_maskand/dataset/without_mask) for easy loading byImageDataGeneratoror similar utilities.Data Preparation: The quality and diversity of your dataset are paramount for robust model performance.Image Preprocessing:Standardization:Resize to 224x224 (or similar, consistent size): CNNs typically require fixed-size input images.224x224is a common input size for many pre-trained models like MobileNetV2.Normalize Pixel Values: Scale pixel intensities from the range[0, 255]to[0, 1]. This helps neural networks train more effectively.Data Augmentation withImageDataGenerator(Keras): This is crucial for preventing overfitting and making your model more robust to variations in real-world images.Apply transformations likerotation_range,zoom_range,width_shift_range,height_shift_range,horizontal_flip.Benefit: This artificially expands your training dataset, introducing variations that your model will likely encounter in real-world scenarios (e.g., different lighting, angles, distances).Build or Import CNN Model:Option 1: Build Your Own Custom CNN:Use KerasSequentialAPI.Start withConv2Dlayers (e.g., 32 filters, 3x3 kernel, ReLU activation).Follow withMaxPooling2Dlayers to reduce spatial dimensions.AddDropoutlayers to prevent overfitting.Flattenthe output of the convolutional layers.End withDenselayers, with the finalDenselayer having 1 unit andsigmoidactivation for binary classification (or 2 units withsoftmaxif using categorical cross-entropy).Benefit: Gives full control and understanding of CNN architecture.Option 2: Load Pre-trained MobileNetV2 (Transfer Learning):ImportMobileNetV2: Load the model fromtf.keras.applications.Exclude Top Layer: Load it withinclude_top=Falseto remove the original classification head.Freeze Base Layers: Setmodel.trainable = Falsefor the loadedMobileNetV2base. This keeps its pre-learned features intact.Add Custom Classification Head: Append newDenselayers and your final outputDenselayer (e.g.,GlobalAveragePooling2D,Densewithsoftmax/sigmoidfor your mask detection).Benefit: Leverages powerful features learned from a vast dataset (ImageNet), leading to higher accuracy with less training data and time.Train the Model:Compile Model:Loss Function: For binary classification, usebinary_crossentropy.Optimizer:Adamis a widely recommended optimizer.Metrics: Trackaccuracy.model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])Train withmodel.fit()ormodel.fit_generator():Feed the augmented image data generated byImageDataGenerator.Specifyepochs(number of full passes over the training data, typically 10-20 is a good starting point for transfer learning).Use avalidation_splitor a separatevalidation_datagenerator to monitor performance on unseen data during training.Callbacks: ConsiderModelCheckpointto save the best model weights during training andEarlyStoppingto stop training if validation loss doesn't improve.Evaluate the Model:Plot Training/Validation Accuracy and Loss: Visualize thehistoryobject returned bymodel.fit(). This helps detect overfitting (where training accuracy continues to rise but validation accuracy plateaus or drops).Test with New Images: Load a few unseen images (not used in training or validation), preprocess them, and pass them through your trained model to get predictions.Check Prediction Confidence: Examine the probability output by thesoftmax/sigmoidlayer to understand the model's confidence in its predictions.Quantitative Metrics: Calculate precision, recall, and F1-score on a separate test set to get a comprehensive understanding of your model's performance on both 'mask' and 'no_mask' classes.Real-Time Face Mask Detection (OpenCV Integration):Access Webcam: Usecv2.VideoCapture(0)to access your default webcam.Loop Through Frames: Read frames continuously from the webcam.Detect Faces (Haar Cascade): Load a pre-trained Haar Cascade classifier for face detection (cv2.CascadeClassifier). Apply it to each frame to get bounding box coordinates for detected faces.Process Detected Faces:Crop Face: Extract the region of interest (ROI) corresponding to each detected face.Resize: Resize the cropped face image to the input size expected by your CNN model (e.g., 224x224).Normalize: Apply the same pixel normalization as during training.Predict: Pass the preprocessed face image to your trained CNN model (model.predict()) to get the mask prediction.Overlay Label: Based on the prediction (e.g., 'With Mask' or 'No Mask') and its confidence, draw a bounding box around the face and display the label (and perhaps a color-coded box: green for mask, red for no mask) on the live video feed usingcv2.rectangle()andcv2.putText().Display Feed: Usecv2.imshow()to display the real-time video feed with annotations.Bonus Features (Advanced Applications & Deployment):Capture Images of People Without Masks: If a "No Mask" prediction is made, programmatically save the corresponding image frame to a designated folder. This can be useful for auditing or compliance reporting.Send Alerts via Email or Telegram Bot: Integrate an alerting system. If a "No Mask" detection persists for a certain duration, trigger an email notification (using Python'ssmtplib) or send a message to a Telegram bot (usingpython-telegram-botlibrary) to a designated recipient.Stream App using Flask or Streamlit:Streamlit (Highly Recommended): Embed your real-time webcam feed directly into a Streamlit web application. Streamlit provides components likest.imagethat can be updated in a loop to display video frames, making it easy to share your real-time detection system.Flask: For more complex web interfaces, use Flask to serve a webcam stream (e.g., usingmultipart/x-mixed-replacefor video streaming) and display predictions in a browser. This would involve a bit more JavaScript on the frontend.Performance Optimization (for Edge Devices): Discuss techniques to optimize the model for faster inference on less powerful hardware, such as model quantization (reducing precision of weights) or usingtf.litefor deployment on edge devices.
Project 7: Face Mask Detection using Computer Vision & Deep Learning Codes:
🔗 View Project Code on GitHub
🚀 Ready to transform your curiosity for data into a career-defining edge?
At Huebits, we don’t just teach Data Science—we empower you to analyze, predict, and lead with hands-on experience, real-world capstone projects, and cutting-edge tools like Python, Scikit-learn, Pandas, TensorFlow, Power BI, and FastAPI.
🧠 Whether you're a student, analyst, or future AI leader, our Industry-Ready DS, AI & ML Program is crafted to make you future-proof. Master machine learning, data analytics, AI-driven solutions, and full-stack deployment—all in one immersive, career-launching journey.
🎓 Next Cohort starts soon!
🔗 Join Now to claim your seat and take the first step into India’s booming ₹800 billion+ AI & Analytics ecosystem.
8. 📑 Document Scanner with OCR and ML Enhancement

- 🔍 Overview: Automating Paperwork with Intelligent Document ProcessingIn an increasingly digital world, physical paperwork remains a stubborn reality across many sectors, from vital records in government and patient forms in healthcare to invoices in finance and student records in education. However, merely scanning documents creates static images. The true power lies in digitizing documents intelligently, which unlocks a vast potential for automation, data extraction, and streamlined workflows.This project empowers you to build a sophisticated Smart Document Scanner that goes far beyond basic image capture. Utilizing your webcam or a mobile camera, the system will not only capture an image of a document but also intelligently correct its perspective (straightening skewed photos), enhance contrast for readability, and then leverage OCR (Optical Character Recognition) technology to extract editable, searchable text. Crucially, you will integrate Machine Learning techniques to significantly enhance OCR accuracy, clean up noisy scans, and even classify different document types (e.g., invoice, resume, ID card), adding a layer of intelligent automation.This is a highly practical and impactful project, perfect for developing intelligent scanning tools that can revolutionize workflows in schools, banks, legal firms, government agencies, and small businesses by converting mountains of physical paper into actionable digital data. You'll gain expertise in computer vision, text processing, and machine learning for real-world document automation.
- 🧠 Skills You’ll Learn:OCR Pipelines: Understand and implement the end-to-end process of converting images of text into machine-readable text, including image acquisition, preprocessing, text recognition, and post-processing.Image Thresholding and Edge Detection: Master fundamental computer vision techniques for image enhancement, crucial for isolating text from backgrounds and identifying document boundaries.Perspective Transformation: Learn how to geometrically transform images to correct distortions caused by skewed camera angles, making text perfectly aligned for accurate OCR.Text Extraction using Tesseract: Gain hands-on experience with Tesseract, one of the most powerful open-source OCR engines, and its Python wrapper (
pytesseract).ML-Enhanced Post-Processing and Document Classification: Apply machine learning principles to refine OCR output (e.g., error correction) and automatically categorize documents based on their content, adding a layer of intelligence beyond simple text extraction. - 🧪 Algorithms Used:Contour Detection (OpenCV): An image processing technique used to identify the outlines of shapes (like the document boundary) within an image. It's crucial for automatically finding the document's corners for perspective correction.Adaptive Thresholding (for Image Preprocessing): A technique that calculates the threshold for binarization (converting an image to pure black and white) for small regions of the image. This is superior to global thresholding in images with varying lighting conditions and helps improve text clarity for OCR.Canny Edge Detection (OpenCV): A multi-stage algorithm used to detect a wide range of edges in images, providing a strong basis for finding the document's outline.Tesseract OCR Engine: While not a "machine learning algorithm" in the typical sense (it's a full OCR engine that internally uses ML), it's the core tool for text recognition. Its performance is heavily reliant on the quality of the preprocessed image.SVM (Support Vector Machine) / Naive Bayes (for Document Classification - Optional):SVM: A powerful supervised learning model used for classification by finding the optimal hyperplane that separates data points into different classes.Naive Bayes: A probabilistic classifier based on Bayes' theorem, often used for text classification due to its simplicity and effectiveness.These would be used if you implement the optional document type classification feature, where the extracted text (or its features) is fed to these algorithms to predict the document type.
- 🛠️ Tech Stack:Python: The central programming language for orchestrating all components.OpenCV (Open Source Computer Vision Library): Indispensable for image capture, all image preprocessing steps (grayscale, blur, thresholding, edge detection, contour detection, perspective transform, resizing).Tesseract OCR Engine: The backend OCR engine that performs the actual text recognition. You'll interact with it via
pytesseract. (Requires Tesseract to be installed separately on your system).Scikit-learn (Optional for Classification): If you implement document classification,scikit-learnwill provide the necessary algorithms (SVM, Naive Bayes), text vectorizers (TF-IDF, CountVectorizer), and evaluation metrics.Streamlit (for Web UI): The recommended tool for creating a clean, interactive, and easy-to-deploy web interface for your document scanner, allowing users to upload images or use their webcam. - 🔩 Step-by-Step Build:Capture or Upload Image:Live Scan via Webcam (
cv2.VideoCapture()): Implement functionality to continuously capture frames from the user's webcam. This enables a "live scan" experience, where the user can position the document in front of the camera.File Upload via Streamlit (st.file_uploader()): Provide an option for users to upload existing document images (JPG, PNG) or even PDF files (which you'd then parse to extract pages as images) directly through the web interface.Input Quality: Acknowledge that the quality of the initial image (lighting, focus, angle) significantly impacts the final OCR accuracy.Preprocess Image for Document Extraction:Convert to Grayscale (cv2.cvtColor()): Convert the captured color image to grayscale. This simplifies subsequent processing steps by reducing dimensionality and focusing on intensity.Apply Gaussian Blur (cv2.GaussianBlur()): Apply a slight Gaussian blur to reduce noise in the image without blurring edges, which helps in more accurate edge detection.Adaptive Thresholding (cv2.adaptiveThreshold()): Convert the grayscale image to a binary (black and white) image. Adaptive thresholding is crucial here as it calculates different thresholds for different regions, handling varying lighting conditions across the document better than a single global threshold. This makes text stand out.Detect Edges withcv2.Canny(): Apply the Canny edge detector to the blurred grayscale image to find strong edges, which are typically the boundaries of the document itself.Find Document Contour (cv2.findContours()): Based on the detected edges, find the largest rectangular contour in the image. This contour is assumed to be the outline of the document.Apply Perspective Transform (cv2.getPerspectiveTransform()andcv2.warpPerspective()): This is a critical step. Once the four corners of the document (from the largest contour) are identified, compute a perspective transformation matrix. This matrix is then used to "warp" the original image, rectifying any skew or distortion caused by the camera angle and presenting the document as if it were scanned perfectly flat. This significantly improves OCR accuracy.Enhance Image for OCR:Re-apply Thresholding (Adaptive or Otsu): After perspective transformation, the document background might still not be perfectly white. Re-applying a robust thresholding method (like Adaptive Thresholding or Otsu's binarization,cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)) can further improve text clarity by making the background uniformly white and text uniformly black.Resize to 300 DPI Equivalent for Sharper Text: Tesseract performs best on images with a resolution of at least 300 DPI (dots per inch). Calculate the necessary scaling factors to effectively "upsample" your straightened document image to this resolution. This makes the text crisper and more recognizable for the OCR engine.Example: If an image is 72 DPI and you want 300 DPI, you'd scale it by300/72 = 4.16.Extract Text with Tesseract:Integratepytesseract: Use thepytesseractlibrary to interface with the Tesseract OCR engine.Extract String: Callpytesseract.image_to_string(enhanced_image_array)to perform the OCR and get the raw extracted text as a string.Clean Extracted Text: OCR output can often contain noise, misrecognitions, or unwanted characters. Perform post-OCR cleaning:Remove excessive line breaks (\n).Remove special characters or non-alphanumeric symbols that are not part of legitimate text.Strip leading/trailing whitespace.Correct common OCR errors (e.g., '1' for 'l', '0' for 'O' - though this can be complex).(Optional) Classify Document Type:Purpose: Automatically categorize the scanned document (e.g., "Invoice," "Resume," "ID Card," "Receipt," "Contract"). This adds intelligent routing and organization capabilities.Training Data: You'll need a dataset of various document types, with their extracted text, labeled with their correct category.Feature Engineering for Classification:Keyword-based features: Check for the presence of specific keywords often found in a document type (e.g., "Invoice Number," "Bill To," "Total Amount" for invoices).Layout features (more advanced): If usingpdfminer.sixor similar, you could extract positions of text blocks, font sizes, heading patterns.TF-IDF Vectorization: Convert the cleaned OCR text of each document into TF-IDF vectors.Train Classifier: Train a Naive Bayes or SVM classifier on these features (or TF-IDF vectors) to predict the document type.Integrate into Pipeline: After OCR, use the trained classification model to assign a type to the scanned document.Export Results:Show OCR Output in UI: Display the extracted text prominently in your Streamlit application.Option to Download: Provide buttons or links to download the OCR'd text in various formats:.txt: Simple plain text file..csv: If you extracted structured data (e.g., a table from an invoice), export it as a CSV.Searchable PDF: Tesseract can also generate a searchable PDF where the original image is preserved and the OCR'd text is embedded invisibly. This is highly useful for archiving.Auto-Save to Folder with Timestamp: Implement functionality to automatically save the extracted text and/or the enhanced image to a local folder with a unique filename (e.g., including a timestamp) for archival purposes.Bonus Features (Advanced Data Extraction & Automation):Add Spellcheck/Grammar Correction using NLP: After OCR, apply a spellchecker (e.g.,pyspellchecker,TextBlob) or grammar correction tool (e.g.,LanguageToolvia its Python API) to the extracted text. This can fix minor OCR errors and improve the overall readability and accuracy of the digitized content.Extract Structured Data (Name, Date, ID, Amounts) using Regex or NER: This is a major value-add.Regex: Use regular expressions to extract specific patterns like email addresses, phone numbers, dates (DD/MM/YYYY), currency amounts ($XX.XX), or invoice numbers.NER (Named Entity Recognition): For more complex extraction (e.g., names, addresses, company names) without predefined patterns, fine-tune a SpaCy NER model on custom training data specific to your document types.Enable Bulk Scanning + Zip Export: For batch processing, allow users to upload multiple document images. Process them sequentially and then offer a single ZIP file containing all the extracted text files and/or searchable PDFs.Integration with Database/Cloud Storage: Automatically upload the extracted text and metadata to a database (e.g., SQLite, PostgreSQL) or cloud storage (e.g., AWS S3, Google Cloud Storage) for persistent storage and further processing.
Project 8: Document Scanner with OCR and ML Enhancement Codes:
🔗 View Project Code on GitHub9. 🎵 Music Genre Classification using Deep Learning (CNN + Audio Analysis)

- 🔍 Overview: Decoding Music with Deep Learning for Intelligent RecommendationsEver wondered how music streaming giants like Spotify, Apple Music, and Amazon Music manage to curate the "perfect" personalized playlists and recommend new artists you'll love? A significant part of their magic lies in music genre classification using advanced machine learning. This project will enable you to build a sophisticated deep learning model that can automatically categorize music tracks into their respective genres (e.g., rock, classical, hip-hop, jazz) based on their intrinsic audio features.You will delve into the fascinating intersection of machine learning and music, learning to perform audio signal processing to extract meaningful features from raw sound files. This involves transforming audio into visual representations like spectrograms or numerical summaries like Mel-Frequency Cepstral Coefficients (MFCCs). These transformed features will then be fed into a Convolutional Neural Network (CNN) – typically used for images, but remarkably effective here for recognizing intricate patterns within these audio-derived "image-like" representations. This project is a perfect blend of creativity and data science, ideal for aspiring data scientists, audio AI enthusiasts, and creative developers looking to explore the frontiers of sound-based AI.
- 🧠 Skills You’ll Learn:Audio Signal Processing: Gain a foundational understanding of how digital audio is represented and how to manipulate it to extract relevant features.Spectrogram/MFCC Generation: Master the techniques to transform raw audio waveforms into visual (spectrograms) or numerical (MFCCs) representations that capture timbre, rhythm, and pitch, making them suitable for deep learning.Deep Learning (CNN for Non-Image Data): Understand how CNNs, traditionally used for images, can be effectively applied to other forms of structured data like audio features (where the 2D arrays of spectrograms/MFCCs behave like images). You'll learn to design and train CNN architectures for classification.Multi-Class Classification: Apply supervised learning principles to categorize data into more than two classes (e.g., 10 distinct music genres), and learn to evaluate model performance across multiple categories.Feature Engineering for Audio: Learn how subtle changes in audio features can define a genre and how to engineer these features for optimal model performance.
- 🧪 Algorithms Used:CNN (Custom-Built): The primary deep learning architecture. You will design and implement a custom Convolutional Neural Network specifically tailored to process the 2D audio features (MFCCs or spectrograms). This involves
Conv2Dlayers for feature extraction,MaxPooling2Dfor dimensionality reduction, andDenselayers for classification.Mel-Frequency Cepstral Coefficients (MFCC): A widely used feature extraction technique in audio processing and speech recognition. MFCCs compactly represent the short-term power spectrum of a sound, particularly the timbre. They mimic how the human ear processes sound frequencies, making them excellent features for genre classification.Softmax Activation for Genre Classification: The final output layer of your CNN will use asoftmaxactivation function. This produces a probability distribution over all possible music genres, indicating the likelihood that an input audio clip belongs to each specific genre. - 🛠️ Tech Stack:Python: The core programming language for all audio processing, deep learning, and potentially UI components.Librosa: A powerful Python library specifically designed for music and audio analysis. It provides robust tools for loading audio files, extracting various audio features (including MFCCs, spectrograms, tempo, rhythm), and performing spectral analysis.TensorFlow / Keras: The leading open-source deep learning framework for building, training, and deploying your CNN model. Keras provides an intuitive API for defining neural network architectures.NumPy: Essential for numerical operations, especially when handling and manipulating the arrays generated from audio features.Matplotlib: For visualizing spectrograms, MFCCs, and plotting training/validation metrics.Jupyter Notebook / Streamlit (for UI):Jupyter Notebook: Excellent for interactive development, experimentation, and presenting your audio feature extraction and model training process step-by-step.Streamlit: Ideal for building a user-friendly web application that allows users to upload audio and get real-time genre predictions.
- 🔩 Step-by-Step Build:Download Dataset:Source: Acquire a suitable and widely used public dataset for music genre classification. The GTZAN Music Genre Dataset is a classic choice, containing 10 genres (e.g., blues, classical, country, disco, hiphop, jazz, metal, pop, reggae, rock), with 100 audio tracks (30 seconds each) per genre.Organization: The dataset is usually organized into subfolders, one for each genre, which simplifies loading and labeling.Extract Audio Features:Load Audio (
librosa.load()): For each audio file, load it into Librosa, which will return the audio time series (as a NumPy array) and the sampling rate.Extract MFCCs or Mel-Spectrograms:MFCCs (librosa.feature.mfcc()): Calculate MFCCs for each audio segment. You can typically extract 13 to 40 coefficients. MFCCs are a great compact representation of timbre.Mel-Spectrograms (librosa.feature.melspectrogram()): Alternatively, generate mel-spectrograms, which are visual representations of the audio spectrum on a mel scale, mimicking human hearing. These can be treated almost like grayscale images.Processing: For each audio file, extract these features over small, overlapping windows (e.g., 20-30 ms frames), generating a sequence of feature vectors over time.Resize Input to Fixed-Length 2D Array: CNNs require fixed-size inputs. Since songs have varying lengths, you'll need to standardize the feature representation:Padding/Truncation: Pad shorter sequences with zeros or truncate longer sequences to a fixed length (e.g., 128 frames for MFCCs).Reshaping: Reshape the extracted MFCCs/spectrograms into a 2D array (e.g.,(num_coefficients, num_frames, 1)) similar to an image (height, width, channels) to be compatible withConv2Dlayers.Prepare Dataset for Deep Learning:Convert Features to NumPy Arrays: Organize all extracted MFCCs (or mel-spectrograms) and their corresponding genre labels into NumPy arrays.Label Encoding: Convert genre names (e.g., "rock", "classical") into numerical labels (e.g., 0, 1, 2...) usingLabelEncoder.One-Hot Encoding (for target variable): Convert the numerical genre labels into one-hot encoded vectors (to_categoricalfrom Keras utils ornp_utils.to_categoricalfromtensorflow.keras.utils). This is required forcategorical_crossentropyloss.Split into Training/Test Sets: Divide your feature arrays and labels into training and testing sets (e.g., 80% train, 20% test) to ensure unbiased model evaluation.Build CNN Model:Input Layer: The input shape of your CNN will match the fixed-length 2D array size of your MFCCs or spectrograms (e.g.,(num_coefficients, num_frames, 1)).Convolutional Layers (Conv2D): Add multipleConv2Dlayers to extract hierarchical features from the audio patterns. UseReLUactivation.Pooling Layers (MaxPooling2D): Reduce the spatial dimensions, making the model more robust to small variations in audio features.Dropout Layers (Dropout): Introduce dropout after convolutional/dense layers to prevent overfitting.Flatten Layer (Flatten): Convert the 2D output of the convolutional layers into a 1D vector before feeding it to dense layers.Dense Layers (Dense): Add fully connected layers.Output Layer (DensewithSoftmax): The finalDenselayer will havenum_genres(e.g., 10) units, with asoftmaxactivation function to output probabilities for each genre.Train the Model:Compile Model:Loss Function: Usecategorical_crossentropyas the loss function, as you have multiple (one-hot encoded) output classes.Optimizer:Adamis a highly effective choice.Metrics: Monitoraccuracy.model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])Train withmodel.fit():Feed your prepared training data (X_train,y_train).Specifyepochs(number of iterations over the entire dataset).Includevalidation_data(your test set or a validation split) to monitor performance on unseen data.Callbacks: UtilizeModelCheckpointto save the model weights that achieve the best validation accuracy, andEarlyStoppingto stop training if validation accuracy doesn't improve after a certain number of epochs, preventing overfitting.Evaluate Model:Test on Unseen Audio Files: Load a few new audio files (not part of your training or test set), preprocess them, and use your trained model to predict their genres.Plot Training/Validation Accuracy and Loss: Visualize thehistoryobject frommodel.fit()to assess model convergence and detect overfitting.Generate Confusion Matrix: Plot a confusion matrix to visually inspect how well your model classifies each genre and identify common misclassifications.Calculate Genre-wise Accuracy, Precision, Recall, F1-Score: Beyond overall accuracy, compute these metrics for each individual genre to understand performance nuances.Deploy It:Save Model: Save your trained Keras model (model.save('music_genre_classifier.h5')) and yourLabelEncoder(usingpickleorjoblib).Build a Streamlit App:Create a Streamlit interface (st.file_uploader) where users can upload an audio track (e.g.,.wav,.mp3).Load the uploaded audio usinglibrosa, extract features, preprocess, and make a prediction using your saved model.Visualize Spectrogram: Uselibrosa.display.specshowwithMatplotlibto display the audio's spectrogram within the Streamlit app.Show Predicted Genre: Display the predicted genre and its confidence score.Optional: Add Audio Player: Includest.audioto allow users to play the uploaded song directly within the app.Bonus Features (Advanced Audio AI & Deployment):Use Transfer Learning with Pre-trained Audio Models: Explore more advanced pre-trained models specifically designed for audio analysis (e.g., Audio Spectrogram Transformer, Wav2Vec 2.0, or pre-trained models from TensorFlow Hub/Hugging Face for audio). This can significantly boost performance, especially with limited data.Add Genre-Based Playlist Suggestions: Based on the predicted genre, connect to a music API (e.g., Spotify API – minding API keys and rate limits) to fetch and suggest similar songs or artists in that genre.Deploy as a Web API: For more robust deployment, containerize your Streamlit app with Docker or deploy your model as a dedicated REST API using Flask or FastAPI, allowing other applications to integrate with your genre classification service.Real-time Audio Input: Extend the Streamlit app to capture real-time audio from the user's microphone, process it in chunks, and predict genres on the fly (more complex due to continuous processing requirements).
Project 9: Music Genre Classification using Deep Learning (CNN + Audio Analysis) Codes:
🔗 View Project Code on GitHub10. 🎥 Movie Recommendation System (Content-Based + Collaborative Filtering)

- 🔍 Overview: The Engine Behind Personalized Digital ExperiencesIn today's digital economy, personalization is key to user engagement and retention. Giants like Netflix, YouTube, and Spotify have mastered this through sophisticated recommendation engines, which are at the core of their thriving platforms. This project offers you a hands-on journey into building a full-fledged movie recommendation system, leveraging both content-based filtering (recommending items similar to what a user liked in the past, based on item metadata) and collaborative filtering (recommending items based on the preferences of similar users or items).You will gain invaluable experience working with large-scale datasets, applying advanced vector similarity techniques (like Cosine Similarity on TF-IDF vectors), and delving into matrix factorization methods (such as Singular Value Decomposition - SVD). By implementing these approaches, you'll not only understand the underlying principles of how real-world platforms personalize user experience at scale but also tackle challenges like data sparsity and the "cold-start" problem (recommending to new users or new items).This project is a must-have for any aspiring ML engineer, data scientist, or product builder looking to specialize in personalization systems, a highly in-demand skill across e-commerce, media, and tech. It provides a robust foundation for understanding how to drive user satisfaction and business growth through intelligent suggestions.
- 🧠 Skills You’ll Learn:Cosine Similarity and TF-IDF for Content-Based Recommendations: Master the techniques to represent textual metadata (like genres, plot summaries, titles) as numerical vectors using TF-IDF, and then calculate cosine similarity to find items (movies) that are semantically similar to each other.Matrix Factorization with SVD for Collaborative Filtering: Understand the principles of collaborative filtering, particularly how Singular Value Decomposition (SVD) can be used to decompose a user-item interaction matrix into latent factors, allowing for efficient prediction of user preferences and recommendation of unseen items.Recommendation Engine Architecture Design: Learn to conceptualize and build the various components of a recommendation system, from data ingestion and feature engineering to model training, prediction, and serving recommendations.Data Visualization and Filtering Techniques: Develop skills in visualizing sparse matrices, understanding user-item interactions, and implementing filters to refine recommendations based on various criteria (e.g., genre, language, popularity).Handling Large & Sparse Datasets: Gain practical experience with datasets that are large in size but sparse in interactions (many users haven't rated many movies), which is common in recommendation systems.
- 🧪 Algorithms Used:TF-IDF (Term Frequency-Inverse Document Frequency) + Cosine Similarity (Content-Based Filtering):TF-IDF: Used to convert descriptive text (e.g., movie genres, keywords, plot summaries) into numerical vectors. It assigns weights to words based on their frequency in a document and their rarity across the entire corpus.Cosine Similarity: Calculates the similarity between two TF-IDF vectors. A higher cosine similarity indicates that the two movies are more similar in their content.SVD (Singular Value Decomposition – Collaborative Filtering): A powerful matrix factorization technique. It decomposes the sparse user-item rating matrix into a set of lower-dimensional "latent factors" for both users and items. These latent factors capture underlying preferences and characteristics, allowing the system to predict how a user would rate an item they haven't seen.Nearest Neighbors (Optional for Collaborative Filtering): Algorithms like
KNNBasicfrom theSurpriselibrary. These are neighborhood-based collaborative filtering methods that find similar users or similar items based on rating patterns and then make recommendations. They can be an alternative or complementary approach to SVD. - 🛠️ Tech Stack:Python: The core programming language for the entire recommendation system.Pandas: Essential for efficient data loading, cleaning, and manipulation of tabular datasets (movies, ratings, users).NumPy: Crucial for high-performance numerical operations, especially when working with matrices for similarity calculations and SVD.Scikit-learn: Provides the
TfidfVectorizerfor content-based features and functions for calculatingcosine_similarity.Streamlit / Flask (for UI):Streamlit: A fantastic library for rapidly building interactive web applications purely in Python, ideal for showcasing the recommendation engine with an intuitive user interface.Flask: A lightweight web framework for building more traditional web applications, providing REST API endpoints if you want to separate your backend logic from the frontend.Surprise Library: A specialized Python scikit for building and analyzing recommender systems. It provides optimized implementations of various collaborative filtering algorithms, including SVD and KNN, making it easy to experiment with different models. - 🔩 Step-by-Step Build:Get the Dataset:Source: The MovieLens dataset is the industry standard for recommender system research and development. It comes in various sizes (e.g.,
ml-latest-small,ml-1m,ml-25m). Start with a smaller version (ml-latest-small) for faster iteration, then scale up.Key Files: You'll typically findmovies.csv(containingmovieId,title,genres) andratings.csv(containinguserId,movieId,rating,timestamp).Loading: Load these CSV files into Pandas DataFrames.Clean & Preprocess Data:Handle Missing Values: Check for and address any missing values in relevant columns (e.g., movie titles, genres, ratings). Depending on the column, you might drop rows, fill with a placeholder, or use imputation.Convert Genres into Feature Vectors (for Content-Based):Thegenrescolumn is usually a string with genres separated by|(e.g., "Action|Adventure|Sci-Fi").Convert this into a list of genres, and then one-hot encode them. Alternatively, for TF-IDF, treat the entire genre string as a "document."Example: If "Action|Adventure" is a genre, it could become[1, 1, 0, 0, ...]for Action, Adventure, Comedy, etc.Create a Movie-User Matrix (for Collaborative Filtering):Pivot theratingsDataFrame to create a matrix where rows areuserIds, columns aremovieIds, and values areratings.This matrix will be very sparse (mostly empty values), as each user only rates a small fraction of all movies. Pandas'pivot_tablewithfill_value=0(orNaNfor Surprise) is useful here.Content-Based Filtering (Item-Item Similarity):Textual Representation: Combine relevant movie metadata (e.g.,title,genres) into a single string for each movie. If aplot_summaryorkeywordsis available, include it for richer content representation.TF-IDF Vectorization:InitializeTfidfVectorizerfromsklearn.feature_extraction.text.Fit the vectorizer on the combined text of all movies and then transform it to get a TF-IDF matrix. Each row represents a movie, and columns are TF-IDF scores for words/genres.Calculate Cosine Similarity:Compute thecosine_similaritymatrix from the TF-IDF matrix. This matrix will havenum_moviesxnum_moviesdimensions, wheresimilarity_matrix[i, j]is the similarity between movieiand moviej.Recommendation Logic:When a user selects a movie they like (e.g., by ID or title), find its row in thesimilarity_matrix.Sort the movies by their similarity scores (excluding the movie itself).Recommend the top N most similar movies.Collaborative Filtering (User-Item Interaction-Based - Optional Advanced):Surprise Library Integration:Load yourratingsDataFrame into Surprise'sDatasetobject. It requiresuser_id,item_id, andratingcolumns.UseDataset.load_from_df().Model Selection:SVD (Singular Value Decomposition): InstantiateSVD()fromsurprise.prediction_algorithms.matrix_factorization.KNNBasic: InstantiateKNNBasic()fromsurprise.prediction_algorithms.knns. This method is based on user-user or item-item neighborhoods.Train/Test Split (for Surprise): Usetrain_test_splitprovided by Surprise to split your rating data into training and test sets.Predict User Rating for Unseen Movies:Train the chosen model (e.g., SVD) on the training set.For a given user, get a list of all movies they haven't rated (trainset.anti_testset).Usemodel.predict()on these unseen user-item pairs to get predicted ratings.Recommend Top-Rated Unseen Movies: Sort the predicted ratings for unseen movies in descending order and recommend the top N movies to the user.Build the Frontend (Streamlit / Flask):User Input Form:Create a Streamlit (st.text_inputorst.selectbox) or Flask-based HTML form where users can input the title of a movie they enjoyed.Handle cases where the movie title is not found (e.g., suggest closest matches).Display Recommended Titles:Based on the user's input, call your backend recommendation logic (either content-based or collaborative).Display the recommended movie titles.Enhance Display: For each recommended movie, show additional metadata like genres, a brief description, and crucially, the movie poster.Tip: You can fetch movie posters using the OMDb API (discussed in bonus features).Interactive Elements: Allow users to like/dislike recommendations (if you're tracking user preferences for a more dynamic system).Evaluate the Recommender:Quantitative Evaluation (for Collaborative Filtering):For SVD or KNN models, use metrics like RMSE (Root Mean Squared Error) or MAE (Mean Absolute Error) on the test set. These measure how close your predicted ratings are to the actual ratings. Lower values indicate better performance. Surprise library has built-inevaluatefunctionality.Qualitative Analysis:Analyze how well the system recommends movies across different genres, user segments, or popularity tiers.Does it recommend diverse movies or does it fall into filter bubbles?Consider the "cold-start" problem: how well does it recommend to new users or suggest new movies?Beyond Offline Metrics: In a real-world scenario, A/B testing (showing different recommendation algorithms to different user groups) and measuring user engagement (click-through rates, watch time, repeat visits) are the ultimate evaluation methods.Bonus Features (Enhance Functionality & User Experience):Add Filtering by Language, Genre, or Release Year: Implement options in the UI to allow users to refine their recommendations. For example, "Show me sci-fi movies released after 2015." This involves adding filters to your recommended list.Integrate with OMDb API for Real-time Metadata/Posters:The MovieLens dataset might not have posters or detailed plot summaries.Use the OMDb API (Open Movie Database API) to fetch additional movie metadata, including plot summaries, directors, cast, and crucially, movie posters, by querying with the movie title or IMDB ID. This vastly improves the visual appeal and information richness of your recommendations.Allow User Login and Track Preferences:Implement a basic user login system (e.g., using simple user IDs or a basic database).Allow users to explicitly rate movies within your app or mark recommendations as "liked" or "disliked."Store these user preferences in a simple database (e.g., SQLite, or even a JSON file for local development).Use these stored preferences to provide more personalized recommendations for returning users over time, allowing your collaborative filtering model to learn from their explicit feedback.Hybrid Recommendation Approaches: Explore combining content-based and collaborative filtering methods. For instance, if a new user has no rating history (cold-start user), use content-based recommendations. Once they rate a few movies, transition to a hybrid or purely collaborative approach.
Project 10: Movie Recommendation System (Content-Based + Collaborative Filtering) Codes:
🔗 View Project Code on GitHub💡 Bonus Ideas to Extend:
· Filter by genre, release year
· Add user login with session tracking
· Integrate with OMDb API to show posters and plot summaries
🏁 Conclusion: From Learner to Leader — Your ML Journey Starts Here
In an AI-powered world, knowing what machine learning is no longer enough. The real differentiator? Knowing how to build, deploy, and explain it. Each of the 10 projects in this guide is more than just a code sample — it’s a career catalyst, handpicked to reflect the trends and demands of 2025 and beyond.
Whether you're:
- 🧑🎓 a final-year student seeking that dream internship,
- 💼 a working professional aiming for an industry switch, or
- 🧠 a curious innovator chasing ideas that shape the future —
These projects are your battlefield training grounds. They teach you to move from classroom concepts to real-world problem solving using Python, TensorFlow, Scikit-learn, Flask, Streamlit, and beyond.
✅ What These Projects Do For You:
- 💼 Build a portfolio that speaks louder than any certificate.
- 🧪 Showcase real-world problem-solving with end-to-end ML pipelines.
- 📊 Practice data storytelling through dashboards, visualizations, and explainable AI.
- 🌐 Learn how to deploy models in the cloud, integrate APIs, and build full-stack ML apps.
- 🧬 Explore advanced concepts like NLP, time-series, computer vision, Edge AI, and recommendation systems.
- 💥 Gain confidence to ace interviews, freelance gigs, or even launch your own startup.
🚀 What's Next?
If you’ve made it this far, you’re already ahead of the curve. But don’t stop at reading. Here’s what to do now:
- 🔗 Clone the GitHub repositories linked in each project.
- ⚙️ Run the code locally or in Colab — see it in action.
- 🧠 Tweak the algorithms, test new datasets, and experiment.
- 🧰 Deploy the best ones as web apps, APIs, or dashboards.
- 📁 Build a killer ML portfolio on GitHub + LinkedIn that screams: "I know my stuff."
🎯 Pro Tip: Pair these projects with a personal blog, YouTube explainer, or Streamlit app. Show the world you’re not just learning ML — you’re living it.
🔮 Final Word
This decade belongs to builders — not watchers.
To those who automate, not those who observe.
To data dreamers who turn ideas into intelligent systems.
So don’t just scroll on. Pick a project. Fire up the code.
Because the future isn’t written in books — it’s coded by you.
About Huebits Industry Ready DS,AI & ML Program
🚀 About This Program
By 2030, AI and Data Science are projected to power over 70% of business decisions, with India’s AI industry alone surpassing ₹800 billion. But here’s the real story — companies aren’t looking for textbook grads. They want data warriors who can build real, scalable ML models, extract insights, and automate decisions with confidence.
That’s where Huebits comes in.
We bridge the industry-academia gap with a hands-on, tool-rich, and project-driven DS, AI & ML Program that empowers you to build, deploy, and optimize real-world AI systems from Day 1 — no fluff, just impact.
🎖️ Certification:
Get certified by Huebits — backed by industry pros, ed-tech mentors, and startup founders — recognized by hiring partners scouting for AI-native talent.
🚀 Ready to lead the data revolution, not just watch it?
🎯 Enroll now in Huebits’ Industry-Ready DS, AI & ML Program and turn your analytical mind into a high-value career weapon.
🔥 "Take Your First Step into the AI Revolution!"
Ready to build real-world AI & Data Science projects that actually create impact?
Join the Huebits Industry-Ready DS, AI & ML Program and gain hands-on experience with Python, machine learning, deep learning, and full-stack deployment — using the very tools top companies demand.
✅ Live Mentorship | 🧠 Project-Based Learning | 💻 Career-Focused Curriculum