Edge AI Revolution: Top 10 Game-Changing Hardware Devices Leading 2025

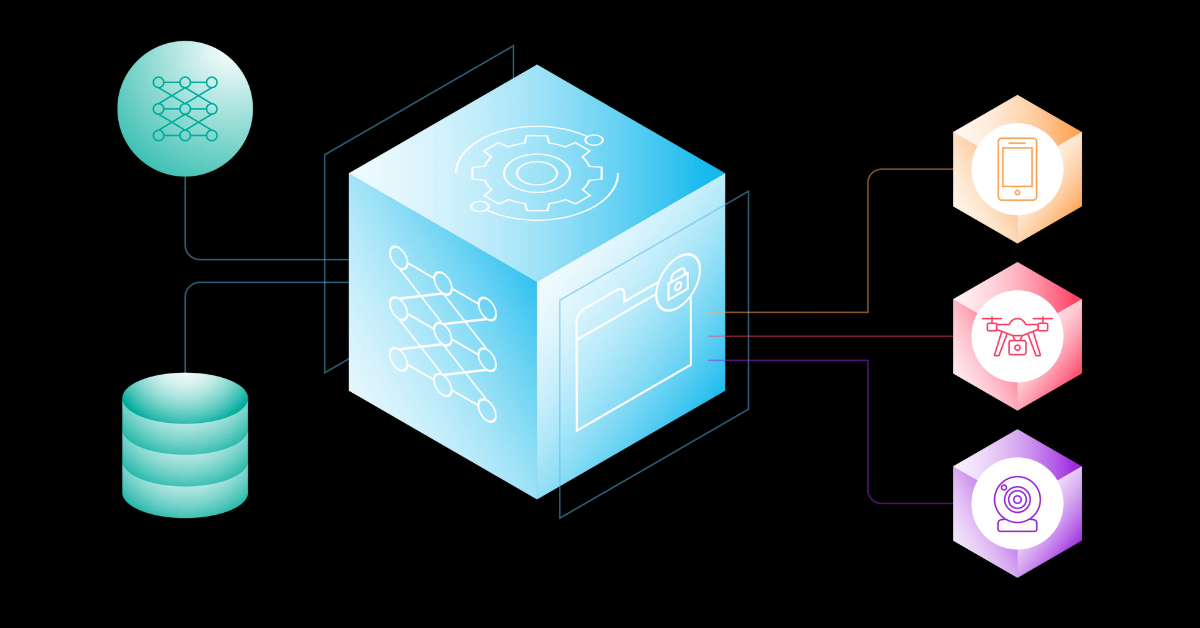
Edge AI isn’t the future — it’s the now hurtling past latency, bandwidth bottlenecks, and data privacy woes. The AI brain is no longer confined to the cloud; it’s living in the wild — on drones, in factories, inside wearables, and at the edge of the network where milliseconds matter and connectivity is a luxury, not a guarantee.
Welcome to 2025, where the best Edge AI hardware isn’t just powerful — it’s optimized, rugged, scalable, and ready to think outside the data center. This paradigm shift is fundamentally reshaping industries, driven by an insatiable demand for real-time insights and autonomous operation in environments where traditional cloud reliance is impractical or impossible.
The "Why" Behind the "Now":
- Hyper-Low Latency: Imagine autonomous vehicles reacting to sudden obstacles in microseconds, or robotic arms in a factory floor adjusting to anomalies instantly. Cloud-dependent AI introduces unavoidable delays that can be catastrophic in such scenarios. Edge AI eliminates these round trips, enabling instantaneous decision-making crucial for safety and efficiency.
- Bandwidth Liberation: The sheer volume of data generated by IoT devices – from high-resolution video feeds to sensor data – would overwhelm network infrastructure if all of it had to be streamed to the cloud for processing. Edge AI processes data locally, drastically reducing the need for constant, high-bandwidth connectivity, making it viable in remote or intermittently connected locations.
- Fortified Data Privacy and Security: Sensitive data, be it patient information from wearables or proprietary manufacturing processes, remains on-device, never leaving the local network. This dramatically reduces the attack surface and helps organizations comply with increasingly stringent data protection regulations like GDPR and CCPA, fostering greater trust and control.
- Enhanced Reliability and Resilience: Operations in remote oil rigs, disaster zones, or even smart cities cannot afford to be crippled by network outages. Edge AI systems can operate autonomously, independent of continuous cloud connectivity, ensuring uninterrupted functionality even in challenging environments.
Edge AI in Action – 2025 Realities:
- Smart Cities & Infrastructure: Edge AI-powered cameras are analyzing traffic patterns in real-time, optimizing signal timings to reduce congestion, and identifying suspicious activities for immediate response, all without sending continuous video streams to central servers. Smart streetlights are adjusting brightness based on pedestrian presence, saving energy.
- Industrial Automation & Robotics: Factories are bristling with AI-powered robots that use on-device intelligence for predictive maintenance, quality control, and adaptive manufacturing. They can detect defects on assembly lines with unparalleled speed and accuracy, minimizing waste and downtime.
- Healthcare at the Point of Care: Wearables and portable medical devices are leveraging Edge AI to continuously monitor vital signs, detect early signs of health issues, and even provide real-time diagnostic assistance to medical professionals in remote clinics, all while keeping sensitive patient data localized.
- Autonomous Systems Everywhere: Beyond self-driving cars, drones are using Edge AI for precision agriculture, inspecting infrastructure for faults, and delivering packages autonomously. Last-mile delivery robots navigate complex urban environments with embedded AI, making real-time decisions about obstacles and routes.
- Retail Innovation: Smart stores are using Edge AI for inventory management, customer flow analysis, and personalized recommendations, all while ensuring customer privacy by processing data anonymously at the source.
The symbiotic relationship between advanced Edge AI algorithms and purpose-built hardware – featuring specialized AI accelerators, low-power designs, and robust enclosures – is the bedrock of this new era. As we move deeper into 2025, the capabilities of Edge AI will only continue to expand, pushing the boundaries of what's possible in a connected, intelligent world.
Table of Content:
1. NVIDIA Jetson Orin Nano
2. Google Coral Dev Board
3. Intel Neural Compute Stick 2 (NCS2)
4. Hailo-8 AI Processor
5. Myriad X VPU (Intel Movidius)
6. Raspberry Pi 5 + AI Accelerator HATs
7. Qualcomm AI Engine (Snapdragon Series)
8. AWS Snowcone with Edge AI Capabilities
9. LatentAI LEIP™ Platform with Supported Hardware
10. Sipeed Maix Series (RISC-V Edge AI Boards)
⚙️ 1. NVIDIA Jetson Orin Nano

Overview:
The NVIDIA Jetson Orin Nano is a series of compact, power-efficient, and high-performance system-on-modules (SOMs) designed specifically for edge AI and robotics applications. As part of the broader Jetson Orin platform, it delivers significant leaps in AI computing power compared to previous generations, making advanced AI inferencing feasible for a wide array of embedded and edge devices. It's built around NVIDIA's Ampere architecture GPU and ARM-based CPUs, providing a balanced architecture for complex AI workloads. Its small size and low power consumption make it ideal for deployment in constrained environments where space, power, and thermal management are critical considerations.
Benefits:
- High AI Performance in a Small Footprint: Delivers up to 40 TOPS of AI performance, allowing for complex neural network inferencing, object detection, segmentation, and natural language processing directly at the edge.
- Energy Efficiency: Designed for low power consumption, enabling deployment in battery-powered devices and reducing operational costs.
- Accelerated Development: Benefits from the robust NVIDIA AI software stack, including CUDA-X, cuDNN, and TensorRT, which significantly accelerate AI model development, optimization, and deployment. Developers can quickly bring their cloud-trained models to the edge.
- Robust Ecosystem: Supported by a vast ecosystem of tools, frameworks (like PyTorch and TensorFlow), libraries, and developer community resources, simplifying the development process.
- Scalability: While powerful, the Orin Nano is part of a larger Orin family, allowing developers to prototype on the Nano and scale up to more powerful Orin modules if higher performance or more complex AI models are needed.
- Real-time Processing: The ability to perform AI inference in real-time on the device is crucial for applications requiring immediate action, such as autonomous navigation or industrial anomaly detection, bypassing latency issues associated with cloud communication.
How it Works:
The NVIDIA Jetson Orin Nano functions as a powerful, self-contained AI computer. Here's a simplified breakdown:
- Input Data Acquisition: Sensors (cameras, LiDAR, microphones, etc.) connected to the Jetson Orin Nano collect raw data from the environment.
- Data Pre-processing (Optional): Basic data cleaning or formatting might occur on the CPU.
- AI Model Deployment: A pre-trained AI model (e.g., a deep neural network for object detection or image classification) is loaded onto the Jetson Orin Nano. These models are typically trained on vast datasets in the cloud and then optimized for efficient execution on the Orin Nano's hardware using tools like NVIDIA TensorRT.
- Hardware Acceleration (GPU & DLA):
- The core of the Orin Nano's power lies in its NVIDIA Ampere architecture GPU, which contains thousands of CUDA cores. These cores are highly parallel processors specifically designed to excel at the matrix multiplications and convolutions that are fundamental to neural networks.
- Some Orin modules also include Deep Learning Accelerators (DLAs), dedicated fixed-function units that provide even greater efficiency for specific deep learning operations. While the Nano generally relies more on its GPU, the underlying architecture is optimized for AI workloads.
- Inference Execution: The input data is fed through the deployed AI model. The GPU (and DLA, if present/used) rapidly performs the complex computations required by the neural network layers, producing an "inference" or prediction.
- Output and Action: Based on the inference, the Jetson Orin Nano can then:
- Trigger an action (e.g., instructing a robot to move, changing a traffic light).
- Output processed data (e.g., bounding box coordinates for detected objects).
- Send condensed insights to the cloud (e.g., "car detected," instead of streaming raw video).
- Software Stack: NVIDIA's JetPack SDK, which includes Linux for Tegra (L4T) OS, CUDA Toolkit, cuDNN, TensorRT, and various libraries, provides the complete software environment for developing, optimizing, and deploying AI applications on the Orin Nano. This integrated stack allows developers to easily transfer their AI models from cloud training environments to the edge device.
💡 Why it’s hot:
With up to 40 TOPS (Tera Operations Per Second) of AI performance, this compact beast is powering robotics, industrial inspection, and intelligent video analytics — all at the edge. It brings server-class AI capabilities to small form factors, enabling sophisticated AI applications where power and space are constraints.
🚀 Use Cases:
- Autonomous delivery bots: Enabling real-time object detection, path planning, and navigation in complex, dynamic environments without constant cloud connectivity.
- Smart city traffic management: Processing live video feeds from intersections to optimize traffic light timings, detect accidents, and monitor pedestrian flow, all locally to reduce latency and bandwidth strain.
- Retail analytics: Analyzing customer behavior, foot traffic patterns, and shelf inventory in real-time within stores to improve operations, personalize experiences, and prevent shrinkage, while maintaining data privacy.
- Industrial inspection: Performing high-speed visual inspection of products on assembly lines to detect defects, ensuring quality control without human intervention.
- Medical imaging analysis at the edge: Assisting clinicians with real-time analysis of ultrasound or X-ray images directly on portable devices.
- Agricultural automation: Powering smart farming robots for crop monitoring, weed detection, and precision spraying.
🧠 Edge Advantage:
Jetson Orin Nano brings the CUDA and TensorRT magic of NVIDIA into embedded systems, giving real-time inferencing like never before. This means developers can leverage the same powerful software stack used for data center AI, optimizing and deploying models with incredible efficiency directly on the device.
To run this DeepStream example (conceptual):
- Install DeepStream SDK: Follow NVIDIA's documentation to install DeepStream SDK on your Jetson Orin Nano. This includes Python bindings.
- Understand GStreamer: DeepStream pipelines are built using GStreamer elements. Familiarity with GStreamer concepts is very helpful.
- Model Configuration: DeepStream's nvinfer plugin uses configuration files (e.g., config_infer_primary_yoloV3.txt) to specify your AI model (TensorRT engine), input/output layers, labels, and other parameters. You would need to adapt these for your specific model.
- Sample Data: The example uses a sample video provided with DeepStream.
- Execution: python your_deepstream_script.py
Project 1: NVIDIA Jetson Orin Nano Codes:
🔗 View Project Code on GitHubKey Takeaways for Code for the Hardware:
- SDKs are your interface: You interact with the Orin Nano's specialized hardware (GPU, DLA, etc.) through NVIDIA's software development kits like JetPack, CUDA, cuDNN, and TensorRT.
- High-level frameworks: You'll typically write your AI applications using high-level frameworks like TensorFlow, PyTorch, or specialized NVIDIA SDKs like DeepStream. These frameworks are designed to automatically leverage the underlying hardware acceleration when properly configured and installed on the Jetson platform.
- Optimization is key: For best performance, especially on edge devices, you often need to optimize your models using tools like NVIDIA TensorRT, which compiles and optimizes neural networks for NVIDIA GPUs.
Always refer to the official NVIDIA Jetson documentation and developer guides for the most up-to-date and detailed instructions on setting up your development environment and writing optimized AI applications.
🔋 2. Google Coral Dev Board

Overview:
The Google Coral Dev Board is a single-board computer (SBC) that serves as a platform for prototyping and deploying AI applications at the edge. Its standout feature is the integrated Edge TPU (Tensor Processing Unit), a purpose-built ASIC (Application-Specific Integrated Circuit) designed by Google specifically for accelerating machine learning inference, particularly with TensorFlow Lite models. Unlike general-purpose GPUs, the Edge TPU is highly optimized for the specific calculations involved in neural networks, allowing it to perform a vast number of operations per second with remarkable power efficiency. The Dev Board provides a complete system, including a system-on-module (SOM) with the Edge TPU, an ARM CPU, Wi-Fi, Bluetooth, and various peripheral interfaces, making it ready for integration into real-world applications.
Benefits:
- Extreme Power Efficiency: The Edge TPU's specialized design enables it to achieve high inference performance with significantly lower power consumption compared to general-purpose CPUs or GPUs. This is critical for battery-powered devices and sustainable edge deployments.
- High Inference Throughput: Despite its low power, the Edge TPU can perform millions of inferences per second, allowing for real-time processing of high-resolution video streams or rapid analysis of sensor data.
- Optimized for TensorFlow Lite: Seamless integration with TensorFlow Lite, Google's lightweight framework for on-device machine learning, simplifies model deployment and optimization.
- Enhanced Privacy and Security: By performing inference locally, sensitive data doesn't need to be sent to the cloud for processing, reducing privacy risks and improving data security.
- Reduced Latency: Eliminating the need to send data to the cloud and wait for a response results in near-instantaneous decision-making, crucial for real-time applications like autonomous robotics or safety systems.
- Offline Capability: Devices can continue to operate and perform AI inference even without an active internet connection, making them robust for remote or intermittently connected environments.
- Compact Form Factor: The small size of the Dev Board and its SOM makes it suitable for integration into a wide range of devices, from small IoT gadgets to larger industrial equipment.
How it Works:
The Google Coral Dev Board leverages the Edge TPU to accelerate machine learning inference:
- Model Training (Off-Device): Machine learning models (e.g., convolutional neural networks for image recognition) are first trained using large datasets, typically in the cloud or on powerful workstations using frameworks like TensorFlow.
- Model Conversion to TensorFlow Lite: Once trained, these models are converted into the TensorFlow Lite format. Crucially, for optimal performance on the Edge TPU, these models also need to be quantized. Quantization reduces the precision of the model's weights and activations (e.g., from 32-bit floating-point to 8-bit integers) without significant loss of accuracy. This process makes the models smaller and much faster to execute on specialized hardware like the Edge TPU.
- Deployment to Coral Dev Board: The quantized TensorFlow Lite model is then deployed to the Coral Dev Board.
- Data Acquisition: Sensors connected to the Dev Board (e.g., a camera capturing video frames, a microphone recording audio) acquire real-world data.
- Inference on Edge TPU: When new data arrives, it is fed to the Edge TPU. The Edge TPU's architecture is specifically designed to perform the tensor operations (matrix multiplications, convolutions, etc.) of the quantized TensorFlow Lite model at extremely high speed and efficiency.
- Output and Action: The Edge TPU returns the inference result (e.g., "object detected," "command recognized," "plant is diseased"). This result is then used by the Dev Board's CPU to trigger an action (e.g., turn on a light, send an alert, activate a robot arm) or provide data to other systems.
- Software Stack: The Coral ecosystem provides a Debian-based Linux OS, TensorFlow Lite runtime, and specific APIs and libraries (like PyCoral) that allow developers to easily load and run their models on the Edge TPU from Python or C++. This streamlines the development process from model training to on-device deployment.
💡 Why it’s hot:
Armed with the Edge TPU (Tensor Processing Unit), it’s small, efficient, and laser-focused on TensorFlow Lite workloads. It's designed to bring powerful, on-device machine learning inference to a wide array of edge devices, particularly those with strict power and size constraints.
🚀 Use Cases:
- IoT sensors with real-time object detection: Enabling smart security cameras to detect intruders, industrial sensors to identify defects on a production line, or wildlife monitoring cameras to classify animal species—all without sending raw video streams to the cloud.
- Smart home hubs: Performing local voice command processing, facial recognition for smart doorbells, or anomaly detection in home environments for security alerts, enhancing privacy and responsiveness.
- Agriculture automation: Powering smart irrigation systems that identify crop health issues, robotic weeders that distinguish between crops and weeds, or pest detection systems directly in the field.
- Medical diagnostic devices: Integrating AI for immediate analysis of medical images (e.g., classifying skin conditions from a camera image) on portable devices, aiding quick diagnoses in remote areas.
- Retail shelf monitoring: Automatically identifying out-of-stock items or misplaced products on shelves using camera feeds processed locally.
🧠 Edge Advantage:
Lightning-fast inferencing with ultra-low power draw — perfect for battery-powered edge devices. The Edge TPU is specifically engineered for high-throughput, low-power inference of TensorFlow Lite models, making it ideal for deployments where efficiency is paramount.
the Google Coral Dev Board runs a Debian-based Linux operating system, and you interact with the Edge TPU through software libraries and APIs, primarily the Edge TPU Python API and TensorFlow Lite.
The core idea is:
- Train your ML model (e.g., in TensorFlow) on a powerful machine.
- Convert and quantize it to a TensorFlow Lite model (.tflite) that is compatible with the Edge TPU. This step is crucial and involves Google's edgetpu_compiler.
- Load and run this optimized TFLite model on the Coral Dev Board using Python (or C++) and the Edge TPU runtime libraries.
Here's an example of how you would do this using Python with the Edge TPU API for a common task like image classification:
Project 2: Google Coral Dev Board Codes:
🔗 View Project Code on GitHubKey Points about "Code for the Hardware" on Coral:
- pycoral library: This is your primary interface in Python for interacting with the Edge TPU. It simplifies loading models, setting inputs, invoking inference, and getting outputs.
- make_interpreter(): This function from pycoral.utils.edgetpu is crucial; it specifically creates an interpreter that knows how to offload operations to the Edge TPU.
- Compiled Models: The Edge TPU requires models that have been specifically compiled for it using the edgetpu_compiler. A standard TensorFlow Lite model will not run directly on the Edge TPU without this compilation step. It will either run on the CPU (if possible) or fail.
- TensorFlow Lite: The underlying framework for models is TensorFlow Lite, but the Edge TPU provides hardware acceleration for specific operations within these models.
For more advanced use cases (e.g., object detection, working with cameras), you'd expand upon this basic structure by adding logic for drawing bounding boxes, streaming video, etc., but the core interaction with the Edge TPU remains similar via the pycoral library.
🚀 Ready to turn raw data into real-world intelligence and career-defining impact?
At Huebits, we don’t just teach Data Science — we train you to build end-to-end solutions that power predictions, automate decisions, and drive business outcomes.
From fraud detection to personalized recommendations, you'll gain hands-on experience working with messy datasets, training ML models, and deploying full-stack data systems — where real-world complexity meets production-grade precision.
🧠 Whether you're a student, aspiring data scientist, or career shifter, our Industry-Ready Data Science Program is your launchpad.
Master Python, Pandas, Scikit-learn, TensorFlow, Power BI, SQL, and cloud deployment — while building job-grade ML projects that solve real business problems.
🎓 Next Cohort Launching Soon!
🔗 Join Now and become part of the Data Science movement shaping the future of business, finance, healthcare, marketing, and AI-driven industries across the ₹1.5 trillion+ data economy.
🧩 3. Intel Neural Compute Stick 2 (NCS2)

Overview:
The Intel Neural Compute Stick 2 (NCS2) is a compact, USB-powered deep learning inference accelerator. It's built around the Intel Movidius Myriad X Vision Processing Unit (VPU), which is specifically designed for low-power, high-performance deep learning inference at the edge. Unlike full-fledged GPUs that are designed for both training and inference, the Myriad X is optimized for the latter, making it highly efficient for deploying pre-trained AI models. The NCS2 acts as an external co-processor, offloading computationally intensive AI inference tasks from the host CPU, thereby speeding up performance and reducing the load on the main processor.
Benefits:
- Portability and Ease of Use: Its USB form factor means it can be plugged into virtually any compatible host device (laptops, embedded systems, SBCs like Raspberry Pi), offering immediate AI acceleration without complex setup.
- Cost-Effective AI Acceleration: Provides an affordable way to add significant AI inference capabilities to existing hardware, making deep learning accessible for a broader range of developers and projects.
- Low Power Consumption: The Myriad X VPU is designed for energy efficiency, making the NCS2 suitable for power-constrained edge deployments.
- Offline AI Capability: Enables AI inference to occur entirely on the edge device, eliminating reliance on cloud connectivity and ensuring continuous operation even in disconnected environments.
- Reduced Latency: Processing data locally minimizes the time delay associated with sending data to the cloud and receiving results, crucial for real-time applications.
- Intel OpenVINO Toolkit Integration: Seamlessly integrates with Intel's OpenVINO (Open Visual Inference and Neural Network Optimization) Toolkit. This powerful toolkit streamlines the process of optimizing and deploying pre-trained deep learning models from various frameworks (TensorFlow, PyTorch, Caffe, etc.) onto Intel hardware, including the NCS2.
- Flexibility for Prototyping: Ideal for rapid prototyping and proof-of-concept development, allowing developers to quickly test AI models in real-world edge scenarios.
How it Works:
The Intel Neural Compute Stick 2 works by offloading deep learning inference computations to its specialized VPU:
- Model Training (Off-Device): An AI model (e.g., for image classification, object detection) is first trained on a powerful workstation or in the cloud using popular deep learning frameworks like TensorFlow, PyTorch, or Caffe.
- Model Optimization with OpenVINO: This is a crucial step. The pre-trained model is then processed using the Intel OpenVINO Toolkit. The toolkit's Model Optimizer converts the model into an Intermediate Representation (IR) that is optimized for Intel hardware, including the Myriad X VPU inside the NCS2. This process often involves quantization (reducing precision to 8-bit integers) and graph optimization to maximize performance.
- Deployment and Host Connection: The optimized model and the application code are deployed onto the host device (e.g., a Raspberry Pi, a laptop). The NCS2 is physically connected to the host device via a USB port.
- Application Logic: The application running on the host device captures input data (e.g., a video frame from a camera).
- Inference Request to NCS2: Instead of the host's CPU or GPU processing the AI inference, the application uses the OpenVINO Inference Engine API to send the input data and a request to perform inference to the connected NCS2.
- VPU Acceleration: The Intel Myriad X VPU within the NCS2 takes the optimized model and the input data. Its array of specialized processing units efficiently executes the neural network operations (convolutions, pooling, activations, etc.) at high speed.
- Result Return: Once the inference is complete, the NCS2 sends the output (e.g., detected objects and their bounding boxes, classification probabilities) back to the host device.
- Host Processing and Action: The host application then interprets these results and takes appropriate action, such as displaying the output, sending an alert, or controlling external hardware.
Essentially, the NCS2 acts as a dedicated accelerator that handles the most computationally intensive part of an edge AI application, freeing up the host's main processor for other tasks and enabling real-time performance.
💡 Why it’s hot: Plug-and-play AI acceleration via USB — think of it as a GPU for your pocket. It's an affordable and highly portable device designed to accelerate deep learning inference on a variety of host systems, transforming ordinary single-board computers and laptops into powerful AI inference engines.
🚀 Use Cases:
- Prototyping Edge AI apps on Raspberry Pi: Enables developers to quickly test and validate AI models on low-power, cost-effective embedded platforms before committing to more specialized hardware.
- Edge video analytics: Accelerating object detection, facial recognition, and activity monitoring on surveillance cameras, drones, or smart retail solutions, allowing real-time insights without constant cloud dependency.
- Real-time medical diagnostics: Assisting in image analysis for conditions like diabetic retinopathy or cancer detection on portable medical devices, speeding up diagnosis in clinics or remote locations.
- Robotics development: Empowering smaller robots with on-board computer vision capabilities for navigation, object manipulation, and interaction.
- Smart industrial sensors: Adding AI capabilities to existing industrial equipment for predictive maintenance, quality control, and anomaly detection.
- Educational AI projects: Provides an accessible entry point for students and hobbyists to experiment with deep learning inference on hardware.
🧠 Edge Advantage: It’s cheap, flexible, and ideal for developers building AI apps without massive hardware overhead. Its USB form factor makes it incredibly versatile and easy to integrate with existing computing systems.
you use Intel's OpenVINO Toolkit (Open Visual Inference and Neural Network Optimization Toolkit) to:
- Optimize your pre-trained AI models (from frameworks like TensorFlow, PyTorch, ONNX, Caffe) for the Myriad X VPU. This converts them into an Intermediate Representation (IR) and often quantizes them.
- Run inference on these optimized models using the OpenVINO Inference Engine API in Python or C++.
Here's an example using the OpenVINO Python API to perform image classification with a pre-trained model on the NCS2.
1. Example: Image Classification with Intel Neural Compute Stick 2 (Python)
This code demonstrates how to load an OpenVINO-optimized model and perform inference on an image using the NCS2.
Prerequisites:
- Intel Neural Compute Stick 2: Plugged into a USB 3.0 port of your host system (e.g., Raspberry Pi, laptop, desktop).
- OpenVINO Toolkit Installation: Install the OpenVINO Toolkit on your host system. Follow the official Intel documentation for the most accurate and up-to-date installation instructions for your specific OS (Linux, Windows, macOS). For a Raspberry Pi or similar ARM-based system, you'd typically follow the "Install OpenVINO Runtime for Raspberry Pi" or "Install OpenVINO Runtime for ARM Processors" guide.
- Crucially: Ensure the install_dependencies.sh script (or equivalent setup for your OS) is run to set up necessary environment variables and udev rules for the NCS2.
- OpenVINO Pre-trained Model: Download a pre-trained and OpenVINO-optimized model from the OpenVINO Model Zoo. A common choice for classification is googlenet-v2.
- You'll need the .xml (model architecture) and .bin (model weights) files.
Project 3: Intel Neural Compute Stick 2 (NCS2) Codes:
🔗 View Project Code on GitHubKey Points about "Code for the Hardware" on NCS2:
- OpenVINO Toolkit: This is the essential software layer. It provides the Model Optimizer (to convert and optimize your model) and the Inference Engine (the runtime API to load and execute models on Intel hardware).
- openvino.runtime.Core: The main entry point for the OpenVINO Python API.
- ie.compile_model(model=model, device_name="MYRIAD"): This is the critical line that tells OpenVINO to compile your model for and utilize the Neural Compute Stick 2.
- Model Format: The NCS2 (via OpenVINO) expects models in its Intermediate Representation (.xml and .bin files). You must convert your original TensorFlow/PyTorch model to this format using OpenVINO's Model Optimizer tool before you can run inference on the NCS2.
- Pre-processing: Image preprocessing (resizing, color channel order, normalization) must match what your specific model was trained on. OpenVINO models often prefer NCHW (batch, channels, height, width) format and may expect specific normalization.
🤖 4. Hailo-8 AI Processor

Overview:
The Hailo-8 is a groundbreaking AI processor specifically engineered for deep learning inference at the edge. Unlike general-purpose CPUs or GPUs that are adapted for AI, the Hailo-8 features a unique, proprietary "dataflow" architecture that is fundamentally optimized for the highly parallel and repetitive computations inherent in neural networks, particularly Convolutional Neural Networks (CNNs). This design allows it to achieve industry-leading performance efficiency (TOPS/Watt) and low latency, making it ideal for real-time, power-constrained applications. It's available as a standalone M.2 module, a PCIe card, or as an embedded chip for integration into various edge devices.
Benefits:
- Unmatched Power Efficiency (TOPS/Watt): Its core strength lies in delivering high AI performance (26 TOPS) while consuming very little power (under 2.5W). This is crucial for battery-operated devices, passive cooling designs, and reducing overall energy costs in large deployments.
- Real-Time, Low-Latency Inference: The dataflow architecture ensures that data moves efficiently through the processor without unnecessary memory transfers, resulting in extremely low latency for AI inference – critical for applications like autonomous driving where milliseconds matter.
- High Performance for CNNs: The architecture is perfectly suited for the computational patterns of CNNs, which are widely used in computer vision applications. This specialized design means it can process complex vision models with high throughput.
- Compact Form Factor: Available in small, embeddable packages (like M.2 cards), allowing for easy integration into a wide variety of edge devices where space is at a premium.
- Scalability and Flexibility: Can be integrated into various systems, from small, low-power IoT devices to more demanding edge servers, offering a flexible solution across different performance needs.
- Developer-Friendly Tools: Supported by the Hailo SDK and comprehensive software tools that facilitate the compilation, optimization, and deployment of popular deep learning frameworks (TensorFlow, PyTorch, ONNX) onto the Hailo-8.
How it Works:
The Hailo-8's innovative dataflow architecture is key to its performance:
- Model Training (Off-Device): Standard deep learning models are trained in the cloud or on powerful workstations using frameworks like TensorFlow or PyTorch.
- Model Compilation and Optimization (Hailo SDK): The trained model is then passed through Hailo's proprietary SDK (Software Development Kit). This SDK compiles and optimizes the neural network graph specifically for the Hailo-8's unique dataflow architecture. This process involves:
- Quantization: Reducing the precision of weights and activations to 8-bit integers, which the Hailo-8 processes highly efficiently.
- Graph Optimization: Reshaping and reordering operations to maximize parallelism and minimize data movement within the chip.
- Dataflow Mapping: The compiler intelligently maps the neural network's operations onto the Hailo-8's processing elements in a way that minimizes external memory access and ensures a continuous flow of data through the chip.
- Deployment to Hailo-8: The optimized, compiled model is then loaded onto the host system (e.g., an embedded board) that incorporates the Hailo-8 processor (via M.2, PCIe, or direct chip integration).
- Input Data Stream: Raw data (e.g., video frames from a camera, sensor readings) is fed from the host system to the Hailo-8.
- Inference Execution (Dataflow): Instead of executing layers sequentially with frequent memory accesses, the Hailo-8 processes data in a continuous "flow." Each processing element within the chip is assigned specific parts of the neural network. Data flows from one element to the next as computations are completed, without needing to be stored in external memory between layers. This highly pipelined and parallel execution is what enables its high throughput and low latency.
- Output and Action: The inference results (e.g., bounding box coordinates, classification labels) are then passed back to the host system. The host application can then use these results to take real-time actions, generate alerts, or store processed insights.
This architectural difference fundamentally distinguishes the Hailo-8 from traditional processor designs, making it exceptionally well-suited for the demanding real-time requirements of edge AI.
💡 Why it’s hot:
26 TOPS (Tera Operations Per Second) in a power envelope of under 2.5W — Hailo-8 is designed for edge devices, not adapted. This means it's built from the ground up to handle complex AI workloads with exceptional efficiency right where the data is generated, making it a standout for power-constrained applications.
🚀 Use Cases:
- Smart surveillance: Enabling advanced analytics like multi-object tracking, abnormal behavior detection, and facial recognition directly on cameras, reducing bandwidth needs and enhancing privacy in smart cities, retail, and enterprise security.
- Automotive systems: Powering advanced driver-assistance systems (ADAS) and autonomous driving features with real-time perception capabilities (e.g., semantic segmentation, object detection, lane keeping) at the vehicle's edge, critical for safety and responsiveness.
- Industrial automation: Integrating into robotics for precise object manipulation and quality inspection, enabling predictive maintenance on machinery by analyzing sensor data, and optimizing production lines with real-time visual feedback.
- Smart home and consumer electronics: Providing on-device AI for voice assistants, personalized media experiences, and intelligent appliance control with enhanced responsiveness and data privacy.
- Edge servers/gateways: Acting as an acceleration backbone for localized AI processing in micro-data centers or network edge nodes, handling aggregated sensor data or video streams from multiple devices.
🧠 Edge Advantage:
Massively parallel architecture that eats CNNs (Convolutional Neural Networks) and spits out real-time results. Its unique data flow architecture minimizes memory access and maximizes computational efficiency, leading to unprecedented performance per watt for deep learning inference.
Project 4: Hailo-8 AI Processor Codes:
🔗 View Project Code on GitHubHailo provides a comprehensive software development kit (SDK) called Hailo TAPPAS Toolkit (formerly Hailo.ai SDK) and the HailoRT SDK to:
- Compile and optimize your pre-trained neural network models (from frameworks like TensorFlow, PyTorch, or ONNX) specifically for the Hailo-8's unique dataflow architecture. This process generates a highly efficient, proprietary model format.
- Run inference on these optimized models using the HailoRT SDK's APIs (C++ or Python) on a host system that contains the Hailo-8 processor (e.g., an M.2 module, PCIe card, or embedded chip).
Important Notes for Hailo-8 Code:
- Installation and Setup are CRITICAL: The hailo_platform and pyhailo libraries are part of the HailoRT SDK, which is a specialized installation. You cannot simply pip install them like standard Python packages. You must follow Hailo's detailed installation guides, which often involve setting up specific environments, drivers, and permissions.
- Model Compilation (.hef): You absolutely must compile your neural network model using Hailo's compiler to produce the .hef file. A standard TensorFlow or ONNX model will not run directly on the Hailo-8. The compilation process handles quantization and optimization for the dataflow architecture.
- Input/Output Layer Names: The input_vstream and output_vstream creation in the example uses placeholder names like 'input_layer_name_0' and 'output_layer_name_0'. You must replace these with the actual input and output layer names of your specific model as defined during its compilation to the .hef file. You can usually find these names by inspecting your .hef file using Hailo's hailo_model_zoo info <your_model.hef> command.
- Data Preprocessing: Pay very close attention to the input data format (CHW vs. HWC, data type, normalization range). The Hailo-8 expects a specific format that was defined during model compilation.
- Error Handling: The try-except blocks are crucial for diagnosing issues with hardware detection or HEF loading.
How to run this code (conceptual steps):
- Set up your hardware: Ensure your Hailo-8 module is correctly installed in your host system (e.g., via M.2 or PCIe) and powered on.
- Install HailoRT SDK: Follow Hailo's specific instructions to install the SDK and necessary drivers on your host OS.
- Compile your model: Use the Hailo TAPPAS Toolkit on your development machine (which might be the same as your host, or a separate machine) to compile your desired neural network model into a .hef file.
- Transfer files: Copy the generated .hef file, your imagenet_labels.txt, and your cat.jpg test image to your host system where the Python script will run.
- Adjust paths/names: Update HAILE_HEF_PATH, LABELS_PATH, IMAGE_PATH, and critically, the input/output layer names in the input_vstream and output_vstream lines in the Python script.
- Run: Execute the Python script.
Bash
python3 hailo_inference_example.py
If everything is set up correctly, you should see the inference time and the top predictions from your model processed by the Hailo-8.
🚀 Ready to turn raw data into real-world intelligence and career-defining impact?
At Huebits, we don’t just teach Data Science — we train you to build end-to-end solutions that power predictions, automate decisions, and drive business outcomes.
From fraud detection to personalized recommendations, you'll gain hands-on experience working with messy datasets, training ML models, and deploying full-stack data systems — where real-world complexity meets production-grade precision.
🧠 Whether you're a student, aspiring data scientist, or career shifter, our Industry-Ready Data Science Program is your launchpad.
Master Python, Pandas, Scikit-learn, TensorFlow, Power BI, SQL, and cloud deployment — while building job-grade ML projects that solve real business problems.
🎓 Next Cohort Launching Soon!
🔗 Join Now and become part of the Data Science movement shaping the future of business, finance, healthcare, marketing, and AI-driven industries across the ₹1.5 trillion+ data economy.
🔐 5. Myriad X VPU (Intel Movidius)

Overview:
The Intel Movidius Myriad X is a third-generation Vision Processing Unit (VPU) from Intel, building upon the legacy of its predecessors (Myriad 1, 2). It's a System-on-Chip (SoC) specifically engineered for vision processing and deep learning inference at the edge. The Myriad X is notable for its integrated Neural Compute Engine, a dedicated hardware accelerator for deep neural network inference, alongside an array of powerful SHAVE (Streaming Hybrid Architecture Vector Engine) cores, programmable vision accelerators, and imaging/video encoders/decoders. This comprehensive set of capabilities allows it to handle the entire vision pipeline – from raw sensor data acquisition to pre-processing, AI inference, and post-processing – all on a single, power-efficient chip. It is the core processor found in devices like the Intel Neural Compute Stick 2.
Benefits:
- High Performance for Vision AI: The combination of the Neural Compute Engine and SHAVE cores provides significant acceleration for deep learning models, particularly those used in computer vision tasks like object detection, semantic segmentation, and facial recognition.
- Ultra-Low Power Consumption: Designed from the ground up for power efficiency, making it suitable for battery-operated devices and embedded systems where thermal management is critical.
- Highly Integrated Solution: Its SoC design integrates multiple functionalities (imaging, AI, video processing) onto a single chip, reducing bill of materials (BOM) costs, board space, and power overhead.
- Real-time Processing: The efficient architecture and dedicated hardware accelerators enable real-time processing of high-resolution video streams and complex AI models, crucial for applications requiring immediate responses (e.g., autonomous systems).
- Depth Processing Capabilities: Features like a stereo depth engine allow it to efficiently process data from stereo cameras, enabling accurate 3D perception, a key component for robotics, AR/VR, and obstacle avoidance.
- Flexible and Programmable: While it has dedicated accelerators, the SHAVE cores offer programmability, allowing developers to implement custom vision algorithms and pre/post-processing logic.
- OpenVINO Ecosystem: Fully supported by Intel's OpenVINO Toolkit, which provides tools to optimize and deploy models from popular frameworks (TensorFlow, PyTorch, Caffe) onto the Myriad X, simplifying the development workflow.
How it Works:
The Intel Movidius Myriad X VPU operates as a specialized co-processor or the primary processor within an edge device, orchestrating the vision and AI pipeline:
- Sensor Input: The Myriad X directly interfaces with various image and depth sensors (e.g., MIPI-CSI cameras, stereo cameras). It can handle multiple camera inputs simultaneously.
- Image Signal Processing (ISP): Raw data from the sensors first passes through the integrated Image Signal Processor. The ISP performs essential tasks like noise reduction, color correction, demosaicing, and exposure control to produce a high-quality image.
- Vision Accelerators (SHAVE Cores): The Myriad X features multiple SHAVE (Streaming Hybrid Architecture Vector Engine) cores. These are highly parallel and programmable vector processors optimized for computer vision algorithms. They handle traditional vision tasks such as feature extraction, warping, image filtering, and pre-processing steps for neural networks. They can also execute parts of custom vision algorithms.
- Neural Compute Engine (NCE) for AI Inference: This is the heart of the AI acceleration. The NCE is a dedicated, fixed-function hardware block designed for efficient execution of deep learning inference.
- Model Optimization (via OpenVINO): Before deployment, deep learning models are trained using frameworks like TensorFlow. Then, the Intel OpenVINO Toolkit's Model Optimizer converts these models into an Intermediate Representation (IR) optimized for the Myriad X's NCE. This often includes quantization (e.g., to INT8 precision) to maximize performance.
- Inference Execution: When an image or video frame is ready, it's passed to the NCE. The NCE rapidly performs the vast number of matrix multiplications and convolutions that make up the neural network, generating inference results (e.g., object bounding boxes, classification scores, depth maps).
- Depth Processing Engine (DPE): For stereo cameras, a dedicated hardware block quickly computes depth maps from two synchronized images, crucial for 3D perception and SLAM.
- Post-processing and Output: The results from the AI inference and other vision tasks are then aggregated. The Myriad X can then:
- Generate control signals for robotics or actuators.
- Encode video streams (H.264/H.265) for efficient transmission.
- Output processed data to a host processor or another part of the system.
- Software Stack: Intel's OpenVINO Toolkit provides the necessary drivers, runtime libraries, and development tools to program and deploy AI and vision applications on the Myriad X, making it easier for developers to harness its power.
In essence, the Myriad X acts as a powerful, integrated "vision brain" at the edge, handling complex visual intelligence tasks directly on the device with high efficiency.
💡 Why it’s hot:
Specialized in vision applications, Myriad X shines in depth perception, gesture recognition, and visual SLAM (Simultaneous Localization and Mapping). It's a highly integrated vision processing unit designed to handle complex computer vision and AI inference tasks with remarkable efficiency at the edge.
🚀 Use Cases:
- Drones: Enabling autonomous navigation, obstacle avoidance, precise landing, and intelligent aerial surveillance through real-time processing of camera and depth sensor data.
- AR/VR (Augmented/Virtual Reality): Powering inside-out tracking for untethered headsets, gesture recognition for intuitive interaction, and real-time environment understanding to seamlessly blend digital content with the real world.
- Smart Glasses: Providing on-device AI for object recognition, text translation, navigation overlays, and hands-free interaction, enhancing user experience without relying on constant cloud connection.
- Robotics: Giving robots advanced visual perception for navigation, object manipulation, human-robot interaction, and complex task execution in logistics, manufacturing, and service industries.
- Smart Cameras & Surveillance: Performing advanced video analytics like people counting, behavior analysis, and vehicle tracking directly at the camera, reducing bandwidth and improving privacy.
- Industrial Automation: Enabling automated quality inspection, robotic guidance, and anomaly detection on the factory floor with high precision and speed.
- Medical Devices: Integrating into portable diagnostic tools for real-time image analysis, assisting in areas like endoscopy or ophthalmology.
🧠 Edge Advantage:
Combines imaging, AI, and control into a single chip — ideal for edge vision intelligence. Its integrated architecture allows for efficient handling of the entire vision pipeline, from sensor input to AI inference and control output, minimizing latency and power consumption.
the code" for the Intel Movidius Myriad X VPU. As with the Intel Neural Compute Stick 2 (NCS2), the Myriad X is primarily accessed and programmed through the Intel OpenVINO Toolkit. The NCS2 contains a Myriad X VPU, so the programming approach is very similar, often identical.
Project 5: Myriad X VPU (Intel Movidius) Codes:
🔗 View Project Code on GitHubThe key steps are:
- Optimize your pre-trained AI models using OpenVINO's Model Optimizer for the Myriad X (specified as MYRIAD device). This generates the Intermediate Representation (IR) files (.xml and .bin).
- Run inference on these optimized models using the OpenVINO Inference Engine API (Python or C++).
- Handle camera input: OpenVINO integrates well with OpenCV, which is commonly used to capture video frames from USB cameras connected to the host system.
Since the Myriad X is often used for visual AI, let's provide an example of real-time object detection from a USB camera using OpenVINO and a pre-trained SSD (Single Shot MultiBox Detector) model.
Key Points about "Code for the Hardware" on Myriad X / Movidius:
- OpenVINO Toolkit is the Bridge: The openvino.runtime API is the standard way to program the Myriad X. It abstracts away the low-level hardware details.
- DEVICE = "MYRIAD": This explicitly tells OpenVINO to use the Myriad X VPU. If you omit this or set it to "CPU", it will run inference on the host's CPU, which will be much slower.
- Model Optimization: You must use OpenVINO's Model Optimizer to convert your original TensorFlow/PyTorch/ONNX models into the .xml (IR) and .bin (weights) format before they can be used by the Myriad X.
- Preprocessing: Image preprocessing is crucial. Ensure your input data (resizing, color channel order, normalization) matches what your specific SSD model expects. SSD models often require a specific input size (e.g., 300x300 or 600x600 for ssd_mobilenet_v2_coco) and normalization (e.g., to [0, 1]).
- Output Parsing: Object detection models output bounding box coordinates and confidences in a specific format (e.g., [image_id, label, confidence, x_min, y_min, x_max, y_max]). You need to parse this output correctly to draw the boxes.
🔍 6. Raspberry Pi 5 + AI Accelerator HATs

Overview:
The Raspberry Pi 5, the latest iteration of the popular single-board computer, provides a significant boost in CPU, GPU, and I/O performance compared to its predecessors. While powerful for general computing tasks, its CPU isn't specifically optimized for heavy deep learning inference. This is where AI Accelerator HATs (Hardware Attached on Top) come in. By integrating specialized AI co-processors like Google's Coral Edge TPU or Intel's Movidius Myriad X VPU (often found in the Intel Neural Compute Stick, which can be adapted or found in HAT form factors), the Raspberry Pi 5 is transformed into a highly capable edge AI device. This modular approach allows users to select the best AI accelerator for their specific workload, leveraging the Pi's versatile connectivity and robust software ecosystem.
Benefits:
- Cost-Effectiveness: The Raspberry Pi 5 itself is affordable, and AI Accelerator HATs offer a relatively inexpensive way to add dedicated AI processing power without investing in much more expensive full-fledged AI development boards.
- Modular Flexibility: Users can choose the AI accelerator that best fits their application needs (e.g., Coral for TensorFlow Lite, Intel for OpenVINO) and easily swap them out. This makes it highly adaptable for different AI models and frameworks.
- Rich Ecosystem and Community Support: The Raspberry Pi boasts an enormous global community, extensive documentation, and a vast array of open-source software and libraries, accelerating development and troubleshooting.
- Compact and Low Power: The combination remains relatively small and power-efficient, making it suitable for deployment in embedded systems and devices with limited space and power budgets.
- Offline AI Capability: By performing AI inference locally on the accelerator HAT, the system operates independently of cloud connectivity, ensuring real-time responsiveness, data privacy, and reliability in remote or intermittently connected environments.
- GPIO and Peripherals: The Pi's rich GPIO (General Purpose Input/Output) pins and standard interfaces (USB, CSI/DSI, PCIe via M.2 HAT) allow for easy connection to cameras, sensors, displays, and other actuators, enabling complete end-to-end AI applications.
- Ease of Prototyping: Its hackable nature and wide availability make it an ideal platform for rapid prototyping and iterating on edge AI concepts.
How it Works:
The Raspberry Pi 5 and an AI Accelerator HAT work together as a symbiotic system:
- Host System (Raspberry Pi 5): The Raspberry Pi 5 acts as the central control unit. Its Broadcom BCM2712 processor (quad-core Arm Cortex-A76) handles the operating system (typically Raspberry Pi OS), general application logic, network communication, and managing peripheral devices (like cameras). It also manages the interface with the AI accelerator.
- AI Accelerator HAT: This is a physical board that connects to the Raspberry Pi, typically via the 40-pin GPIO header, a dedicated PCIe connector (on Pi 5), or a USB port (for USB-based accelerators like the Intel NCS2 or Coral USB Accelerator). It contains the specialized AI co-processor (e.g., Google's Edge TPU or Intel's Myriad X VPU).
- Model Training (Off-Device): Deep learning models are trained on powerful machines or in the cloud using frameworks like TensorFlow or PyTorch.
- Model Optimization and Conversion: The trained models are then optimized and converted into a format suitable for the specific AI accelerator (e.g., TensorFlow Lite for Coral, OpenVINO IR for Intel Myriad X). This process often involves quantization (reducing precision) to make the models more efficient for edge hardware.
- Data Acquisition: Cameras, microphones, or other sensors connected to the Raspberry Pi (via CSI, USB, or GPIO) capture raw data from the environment.
- Inference Offloading: When the application running on the Raspberry Pi needs to perform AI inference (e.g., detect objects in a video frame), instead of using the Pi's main CPU (which would be slow for complex models), it sends the relevant data to the AI Accelerator HAT.
- Accelerated Inference: The dedicated AI co-processor on the HAT (Edge TPU or Myriad X) takes over the computation. It rapidly executes the neural network operations, leveraging its specialized architecture for high throughput and low power consumption.
- Result Return: The AI accelerator sends the inference results (e.g., detected objects, classifications, predictions) back to the Raspberry Pi 5.
- Host Processing and Action: The Raspberry Pi's CPU then processes these results. This could involve:
- Overlaying bounding boxes on a video stream.
- Triggering a specific action (e.g., opening a door, sending a notification).
- Storing metadata locally or sending condensed insights to the cloud.
- Software Stack: The combination relies on the operating system on the Raspberry Pi (e.g., Raspberry Pi OS) and specific SDKs and libraries provided by the AI accelerator vendor (e.g., PyCoral for Google Coral, OpenVINO for Intel). These software layers enable the seamless communication and task offloading between the Pi and the accelerator.
This synergistic approach allows the Raspberry Pi 5 to handle the general-purpose computing and I/O, while the AI Accelerator HAT delivers the specialized, power-efficient horsepower needed for demanding deep learning inference at the edge.
💡 Why it’s hot: The iconic dev board leveled up in 2025 with the Raspberry Pi 5 — pair it with a Google Coral (Edge TPU) or Intel (Movidius Myriad X VPU) AI Accelerator HAT, and you’ve got a fully functional, highly versatile, and cost-effective edge AI node. This combination leverages the Pi's broad ecosystem with specialized AI hardware.
🚀 Use Cases:
- Hobbyist AI projects: From smart pet feeders with object recognition to intelligent garden monitoring systems that detect plant diseases, enabling endless DIY AI innovations.
- Home automation: Creating local smart home hubs that process voice commands offline, perform facial recognition for access control, or manage energy consumption based on occupancy detection, enhancing privacy and responsiveness.
- Decentralized ML inference: Deploying small, distributed AI nodes for tasks like environmental monitoring (air quality, noise levels), localized traffic analysis, or distributed security camera networks where data privacy and low latency are paramount.
- Educational platforms: Providing an accessible and affordable platform for students and educators to learn about edge AI, robotics, and embedded systems.
- Prototyping and proof-of-concept: Ideal for startups and developers to quickly prototype and validate edge AI solutions before scaling to more specialized or custom hardware.
- Edge video analytics: Developing smart security cameras, motion-triggered recorders, or wildlife monitoring systems that perform real-time object detection and classification locally.
🧠 Edge Advantage:
Modular, affordable, hackable — the maker’s dream turned enterprise prototype. This combination offers unparalleled flexibility and cost-effectiveness, allowing developers to tailor solutions precisely to their needs and leverage a massive community and readily available resources.
the code" for the Raspberry Pi 5 combined with AI Accelerator HATs. This is a modular setup, meaning the "code" will primarily involve:
- Standard Python/Linux code running on the Raspberry Pi 5.
- Specific SDKs/APIs to interact with the chosen AI Accelerator HAT (e.g., Google Coral's pycoral for the Edge TPU, or Intel OpenVINO for Myriad X VPUs).
- OpenCV for camera integration and drawing.
I'll provide an example using the Google Coral USB Accelerator HAT (as it's a very popular and straightforward option for RPi 5). The principles for an Intel-based HAT would be similar, just swapping the pycoral library for OpenVINO.
Project 6: Raspberry Pi 5 + AI Accelerator HATs Codes:
🔗 View Project Code on GitHubKey Points about "Code for the Hardware" on Raspberry Pi 5 + AI HATs:
- Modular Approach: The Raspberry Pi 5 provides the general-purpose computing, handles the camera input, and displays the output. The AI Accelerator HAT (like the Coral USB Accelerator) is solely responsible for accelerating the deep learning inference.
- pycoral Library: This Python library (or the C++ equivalent) is the interface to the Google Edge TPU. It simplifies model loading and inference execution on the accelerator.
- Edge TPU-Compiled Models: Just like with the Coral Dev Board, the Coral USB Accelerator requires models that have been specifically compiled for the Edge TPU using Google's edgetpu_compiler.
- OpenCV for Camera: OpenCV is widely used on Raspberry Pi for handling camera input, image manipulation, and drawing visualizations (like bounding boxes).
- Performance: The Raspberry Pi 5's improved CPU performance helps with general tasks and video processing, while the dedicated AI HAT offloads the most computationally intensive part (inference), leading to excellent real-time performance.
- Headless Operation: You can also run this script without a display (e.g., via SSH) if you're only saving the processed frames or sending data to another system. In such cases, remove cv2.imshow and cv2.waitKey.
🚀 Ready to turn raw data into real-world intelligence and career-defining impact?
At Huebits, we don’t just teach Data Science — we train you to build end-to-end solutions that power predictions, automate decisions, and drive business outcomes.
From fraud detection to personalized recommendations, you'll gain hands-on experience working with messy datasets, training ML models, and deploying full-stack data systems — where real-world complexity meets production-grade precision.
🧠 Whether you're a student, aspiring data scientist, or career shifter, our Industry-Ready Data Science Program is your launchpad.
Master Python, Pandas, Scikit-learn, TensorFlow, Power BI, SQL, and cloud deployment — while building job-grade ML projects that solve real business problems.
🎓 Next Cohort Launching Soon!
🔗 Join Now and become part of the Data Science movement shaping the future of business, finance, healthcare, marketing, and AI-driven industries across the ₹1.5 trillion+ data economy.
💼 7. Qualcomm AI Engine (Snapdragon Series)

Overview:
The Qualcomm AI Engine is not a single piece of hardware but a comprehensive, integrated architecture within Qualcomm's Snapdragon SoC platforms. It's a heterogeneous computing platform that intelligently leverages various specialized processing cores to accelerate AI workloads. This includes:
- Qualcomm Hexagon DSP (Digital Signal Processor): Highly optimized for scalar, vector, and tensor computations, crucial for neural network processing.
- Qualcomm Adreno GPU (Graphics Processing Unit): Capable of parallel processing, which is beneficial for certain AI tasks, especially those involving image and video data.
- Qualcomm Kryo CPU (Central Processing Unit): Handles general-purpose computing and manages the orchestration of AI tasks across the other components.
- Qualcomm Sensing Hub: A low-power, always-on AI processor for context awareness and sensor fusion, designed to handle lighter AI tasks continuously without waking the main cores.
The strength of the Qualcomm AI Engine lies in its ability to dynamically allocate AI tasks to the most efficient core (CPU, GPU, or DSP/NPU) based on the specific workload, ensuring optimal performance per watt.
Benefits:
- Ubiquitous On-Device AI: By integrating AI acceleration directly into the core mobile SoC, Qualcomm has democratized edge AI, making powerful machine learning capabilities available on billions of devices globally.
- Exceptional Power Efficiency: The heterogeneous architecture allows AI computations to be offloaded to the most power-efficient core for a given task, significantly extending battery life for AI-driven features.
- Ultra-Low Latency: Processing AI on the device eliminates network round trips, leading to near-instantaneous responses for critical applications like AR/VR tracking, voice commands, and real-time photography.
- Enhanced Privacy and Security: Sensitive user data (e.g., biometric information, personal photos) remains on the device, reducing the risk of exposure and improving compliance with data privacy regulations.
- Offline Functionality: AI-powered features can operate fully without an internet connection, crucial for reliability in areas with poor connectivity or for applications requiring continuous operation.
- Scalability: The Snapdragon platform offers a range of performance tiers, allowing developers to scale their AI applications from entry-level devices to high-end flagship products.
- Comprehensive Software Tools: Qualcomm provides a robust AI software stack, including the Qualcomm AI Engine Direct SDK, which allows developers to optimize and deploy models from popular frameworks (TensorFlow, PyTorch, ONNX, Caffe) directly onto Snapdragon devices.
How it Works:
The Qualcomm AI Engine works by intelligently distributing and accelerating AI inference tasks across its various specialized cores:
- Model Training (Off-Device): Machine learning models are trained in the cloud or on powerful servers using standard deep learning frameworks.
- Model Optimization (Qualcomm AI Engine Direct SDK): Trained models are then processed using Qualcomm's AI Engine Direct SDK. This SDK optimizes the models for the Snapdragon platform's heterogeneous architecture. This involves:
- Quantization: Converting models to lower precision (e.g., INT8) for faster and more power-efficient execution on the DSP/NPU.
- Graph Partitioning and Layer Mapping: The SDK analyzes the model's structure and intelligently maps different layers or operations to the most suitable processing unit (Hexagon DSP/NPU for tensor operations, Adreno GPU for parallel image processing, Kryo CPU for control flow or less common operations).
- Deployment to Snapdragon Device: The optimized model and the application logic are deployed onto the Snapdragon-powered smartphone, XR headset, or other device.
- Input Data Acquisition: Sensors on the device (cameras, microphones, accelerometers, gyroscopes) continuously capture real-world data.
- Intelligent Workload Allocation: When an AI inference request comes in (e.g., a photo is taken for processing, a voice command is spoken), the Qualcomm AI Engine's runtime intelligently determines the optimal core(s) to execute the specific AI task based on the model's characteristics and the current system load.
- Accelerated Inference: The chosen processing unit(s) (Hexagon DSP, Adreno GPU, or Kryo CPU) then execute the inference operations in a highly optimized and parallel manner. For always-on, low-power sensing, the Qualcomm Sensing Hub might handle initial, lighter AI tasks.
- Output and Application Response: The inference results (e.g., "object detected," "speech command recognized," "image enhanced") are immediately available to the application. The application then uses these results to perform a desired action, provide a feature to the user, or send summarized data.
This integrated and adaptive approach allows Qualcomm AI Engine to deliver high-performance, power-efficient AI directly on billions of devices, making intelligence truly mobile and edge-native.
💡 Why it’s hot:
5G + Edge AI = mobile intelligence that scales across billions of devices. Qualcomm's AI Engine is not a standalone chip but a suite of hardware and software components integrated into their ubiquitous Snapdragon System-on-Chips (SoCs), bringing powerful, on-device AI capabilities to the forefront of the mobile and extended reality (XR) revolution.
🚀 Use Cases:
- Smartphones: Enabling advanced features like real-time computational photography (e.g., enhanced night mode, portrait mode effects, super-resolution zoom), on-device voice assistants, personalized content recommendations, intelligent power management, and highly accurate biometric authentication.
- Edge-native AR/VR/XR devices: Powering immersive experiences with simultaneous localization and mapping (SLAM), gesture recognition, eye tracking, real-time object understanding, and contextual awareness directly on headsets and smart glasses for untethered operation and seamless interaction.
- Intelligent wearables: Providing on-device AI for continuous health monitoring (e.g., activity tracking, sleep analysis, heart rate variability), smart notifications, and proactive safety features, extending battery life and enhancing user privacy.
- Automotive infotainment and ADAS: Enabling intelligent cockpit experiences with driver monitoring, personalized interactions, and supporting some levels of advanced driver-assistance features for enhanced safety and convenience.
- IoT and Robotics: Serving as the brain for sophisticated IoT devices requiring on-device intelligence, such as smart cameras with advanced analytics, and compact robots needing real-time perception and decision-making capabilities.
🧠 Edge Advantage:
Massive AI performance baked right into mobile SoCs — no cloud dependency needed. This tight integration ensures extreme power efficiency, low latency, and enhanced privacy, making advanced AI ubiquitous in personal and embedded devices.
Here’s how to wield the Qualcomm Neural Processing SDK (NPSDK) with C++ and Java. We’ll break it into chunks like a disciplined dev squad — from model conversion to native Android inferencing code.
Project 7: Qualcomm AI Engine (Snapdragon Series) Codes:
🔗 View Project Code on GitHubHere’s how to wield the Qualcomm Neural Processing SDK (NPSDK) with C++ and Java. We’ll break it into chunks like a disciplined dev squad — from model conversion to native Android inferencing code.
🧠 Tips for Production-Level Integration
· Use SNPE runtime fallback: try GPU → DSP → CPU
· Batch pre-process using OpenCV + NDK for faster throughput
· For larger models: quantize before converting (snpe-dlc-quantize)
· Deploy via Android Studio with C++ support module
📚 Resources You’ll Need:
https://www.qualcomm.com/developer/software/neural-processing-sdk-for-ai?redirect=qdn
🛰️ 8. AWS Snowcone with Edge AI Capabilities

Overview:
AWS Snowcone is the smallest member of the AWS Snow Family of edge computing, data migration, and data transfer devices. It's designed to bring AWS computing and storage capabilities to harsh, disconnected, or distributed environments outside of traditional data centers. Snowcone is built to be rugged, highly portable (weighing only 4.5 lbs/2.1 kg), and secure, enabling customers to collect, process, and analyze data at the edge, and then seamlessly transfer it to AWS cloud services when connectivity is available.
For Edge AI capabilities, Snowcone allows users to deploy Amazon EC2 instances with suitable compute (CPU or sometimes a specific instance type that might feature acceleration if available/specified for Snowcone, though its primary focus is not high-end GPU acceleration like some other dedicated AI boxes), running machine learning inference workloads. It's particularly well-suited for scenarios where data residency, intermittent connectivity, and physical ruggedness are more critical than raw, cutting-edge AI performance provided by dedicated AI accelerator hardware.
Benefits:
- Extreme Portability & Ruggedness: Its small size and durable design (built to withstand drops, extreme temperatures, and vibrations) make it ideal for deployment in challenging and remote environments.
- Offline Operation & Intermittent Connectivity: Snowcone enables full-fledged compute and storage operations locally, even when completely disconnected from the internet. Data can be processed and analyzed on-site, with results or collected raw data synced back to AWS when connectivity is restored via AWS DataSync.
- AWS Integration: Provides a consistent AWS experience at the edge. Users can run Amazon EC2 instances and AWS IoT Greengrass, allowing them to leverage familiar AWS services and tools for deploying and managing edge AI applications.
- Enhanced Security & Tamper Resistance: Designed with multiple layers of security, including tamper-evident seals, encryption, and robust physical security features, ensuring data integrity and protection in sensitive environments.
- Data Transfer Simplification: Facilitates efficient data transfer from the edge to the AWS cloud. For large datasets in disconnected scenarios, users can ship the physical Snowcone device back to AWS for direct data ingestion.
- Reduced Latency & Bandwidth Usage: By processing data locally, it eliminates the need to send all raw data to the cloud for analysis, significantly reducing latency and bandwidth requirements.
- Hybrid Cloud Consistency: Extends the AWS cloud to the edge, maintaining a consistent environment for developers and operations teams.
How it Works:
AWS Snowcone with Edge AI capabilities involves several key steps:
- Device Provisioning & Shipping:
- You order an AWS Snowcone device from the AWS Management Console.
- You select the desired Amazon EC2 instance type (e.g., sbe1 instances for Snowcone) and specify the software you want pre-installed, including your edge AI application and associated ML models.
- AWS prepares the Snowcone and ships it to your remote location.
- On-Site Deployment & Setup:
- Once received, you connect Snowcone to power and a local network (if available).
- You use the AWS OpsHub for Snow Family application (running on a laptop) to unlock and manage the Snowcone device locally.
- You launch your pre-configured Amazon EC2 instance(s) running your edge AI application.
- Local Data Collection & AI Inference:
- Sensors (cameras, industrial sensors, drones) at the edge environment collect raw data.
- This data is ingested into the Snowcone's local storage.
- Your deployed AI application, running on the EC2 instance(s) within Snowcone, accesses this local data.
- The application performs real-time or batch machine learning inference using the pre-loaded ML models. For example, a computer vision model might detect objects in a video feed, or a time-series model might predict equipment failure.
- The processed insights or filtered data are stored locally.
- Data Synchronization to AWS Cloud (when connected):
- When an internet connection becomes available (intermittently or continuously), Snowcone can use AWS DataSync to securely and efficiently synchronize the processed insights, critical alerts, or even select raw data back to your AWS S3 buckets or other AWS services in the cloud.
- For very large datasets or in completely disconnected environments, you can simply return the physical Snowcone device to AWS, where the data will be securely ingested into your S3 buckets.
- Cloud-Side Management & Analytics:
- In the AWS cloud, you can further analyze the aggregated data, retrain and update your ML models based on new edge insights, and then push updated models or applications back to your Snowcone devices.
- AWS IoT Greengrass can be deployed on Snowcone to provide local compute, messaging, data caching, and sync capabilities, further extending AWS IoT and machine learning inference to edge devices.
In essence, AWS Snowcone acts as a highly resilient and secure mini-data center at the edge, allowing critical AI processing to happen locally and seamlessly integrating with your broader AWS infrastructure.
💡 Why it’s hot:
Rugged, portable edge compute from Amazon — with integrated ML inferencing and data sync to AWS. Snowcone extends the AWS cloud computing environment to the extreme edge, offering a highly secure, tamper-resistant, and robust solution for deploying AI in environments where traditional connectivity is unreliable or non-existent.
🚀 Use Cases:
- Remote field operations: Performing real-time object detection on aerial drone footage for surveying in agriculture, oil & gas exploration, or environmental monitoring in areas with no internet access. Processing sensor data from remote pipelines or communication towers for predictive maintenance.
- Military-grade AI deployments: Enabling tactical AI applications on battlefields, in forward operating bases, or on naval vessels, where secure, offline AI processing and minimal data exfiltration are paramount for situational awareness and rapid decision-making.
- Offline-first industrial AI: Running machine learning models for quality control, anomaly detection, or predictive maintenance directly on factory floors, mining sites, or construction zones, especially in locations where constant network connectivity to the cloud is not feasible or desired.
- Disaster response and emergency services: Providing immediate local AI processing for critical applications like identifying survivors in collapsed structures, assessing damage from natural disasters, or managing resource allocation in areas where infrastructure is compromised.
- Content creation and data ingestion in remote locations: Processing and cataloging vast amounts of media (e.g., film sets, scientific expeditions) on-site with AI for efficient storage and later transfer to AWS.
🧠 Edge Advantage:
Secure, tamper-resistant, and built for the edge of civilization. Snowcone combines AWS's robust security features with physical durability, making it an ideal choice for mission-critical AI deployments in the harshest and most sensitive environments. It's a true hybrid cloud solution for the far edge.
You’re going to:
1. Train/compile a model with SageMaker Neo
2. Build a Docker container to run inference
3. Deploy that to AWS Greengrass on Snowcone
4. Use Lambda (local) to trigger inference
Goal: Deploy and run ML models on AWS Snowcone using SageMaker Neo, AWS Greengrass v2, Lambda, and Docker containers
Language Stack: Python for model & Lambda, Bash for deployment, Docker for packaging
Target Runtime: Offline-capable, hardware-accelerated inferencing
Project 8: AWS Snowcone with Edge AI Capabilities Codes:
🔗 View Project Code on GitHub🧭 Field Deployment Checklist (Snowcone AI Ops):
· Model compiled using SageMaker Neo
· Docker container with TFLite/PyTorch
· Greengrass recipe and deployment ready
· Snowcone has outbound sync (for S3 if needed)
· Optional local UI via Flask or Nginx
🚀 Ready to turn raw data into real-world intelligence and career-defining impact?
At Huebits, we don’t just teach Data Science — we train you to build end-to-end solutions that power predictions, automate decisions, and drive business outcomes.
From fraud detection to personalized recommendations, you'll gain hands-on experience working with messy datasets, training ML models, and deploying full-stack data systems — where real-world complexity meets production-grade precision.
🧠 Whether you're a student, aspiring data scientist, or career shifter, our Industry-Ready Data Science Program is your launchpad.
Master Python, Pandas, Scikit-learn, TensorFlow, Power BI, SQL, and cloud deployment — while building job-grade ML projects that solve real business problems.
🎓 Next Cohort Launching Soon!
🔗 Join Now and become part of the Data Science movement shaping the future of business, finance, healthcare, marketing, and AI-driven industries across the ₹1.5 trillion+ data economy.
9. LatentAI LEIP™ Platform with Supported Hardware
Overview:
LatentAI LEIP™ (Latent AI Efficient Inference Platform) is a comprehensive software platform designed to address one of the most critical challenges in Edge AI: effectively deploying complex deep learning models onto resource-constrained hardware. It's not a piece of hardware itself, but rather a powerful suite of tools that enables AI engineers to optimize, compress, and quantize pre-trained neural network models so they can run efficiently on a wide variety of edge devices, from microcontrollers to embedded GPUs and custom ASICs. LEIP achieves this by employing advanced techniques like Neural Network Pruning, Quantization (including 8-bit, 4-bit, and even binary quantization), and Architecture Search (Neural Architecture Search - NAS), all while striving to maintain or even improve model accuracy. Its hardware-agnostic nature provides immense flexibility for developers.
Benefits:
- Significant Model Compression: LEIP can dramatically reduce the size of neural networks, making them small enough to fit into the limited memory of edge devices.
- High Performance on Constrained Hardware: By optimizing the model for the target hardware's architecture and capabilities, LEIP enables faster inference speeds and lower latency, even on low-power processors.
- Maintains or Improves Accuracy: Unlike naive compression techniques, LEIP employs intelligent algorithms to ensure that the accuracy of the compressed and quantized model is preserved, or in some cases, even enhanced.
- Hardware Agnostic: A core strength of LEIP is its ability to target a vast array of hardware platforms (CPUs, GPUs, DSPs, NPUs, FPGAs, Microcontrollers) from different vendors. This gives developers freedom in hardware selection.
- Reduced Power Consumption: Smaller, more efficient models require fewer computations, leading to lower power draw, which is critical for battery-operated and always-on edge devices.
- Faster Development Cycle: By providing automated optimization tools, LEIP streamlines the process of taking a cloud-trained model and preparing it for edge deployment, significantly reducing development time and effort.
- Unlocks New Use Cases: Enables the deployment of sophisticated AI in devices and scenarios that were previously impossible due to computational or power limitations (e.g., TinyML, highly embedded systems).
- Enhanced Data Privacy: Running AI inference on-device means less data needs to be sent to the cloud, enhancing privacy and reducing data transfer costs.
How it Works:
The LatentAI LEIP™ Platform fundamentally operates by transforming a "standard" pre-trained deep learning model into a highly optimized version suitable for edge deployment. Here’s a conceptual flow:
- Original Model (Cloud/Workstation Trained): An AI model (e.g., a TensorFlow, PyTorch, or ONNX model) is initially trained on large datasets using powerful cloud infrastructure or high-end workstations. This model is often large and requires significant compute resources.
- LEIP Platform Ingestion: The pre-trained model is imported into the LEIP platform.
- Model Optimization and Compression (Core LEIP Process): This is where LEIP performs its magic using a combination of techniques:
- Quantization: LEIP quantizes the model's weights and activations, typically from floating-point (FP32) to lower-bit integer representations (e.g., INT8, INT4, or even binary). It employs sophisticated post-training quantization and quantization-aware training techniques to minimize accuracy loss during this process.
- Pruning: LEIP can identify and remove redundant or less important connections (weights) and even entire neurons or filters within the neural network. This dramatically reduces the model's size and computational requirements.
- Knowledge Distillation: In some advanced scenarios, LEIP might use knowledge distillation to transfer knowledge from a large "teacher" model to a smaller "student" model, improving the student model's accuracy despite its reduced size.
- Neural Architecture Search (NAS) (for some offerings): For highly specific performance targets, LEIP may incorporate NAS to automatically design optimal neural network architectures that are inherently efficient for the target hardware.
- Hardware-Specific Compilation (Targeting): Once optimized, LEIP compiles the compressed model for the specific target hardware. This involves generating highly efficient code (e.g., C/C++) or a specialized graph representation that can leverage the unique capabilities (e.g., DSPs, NPUs, specific instruction sets) of the chosen edge processor. This step ensures that the model runs as fast and efficiently as possible on the target device.
- Deployment: The optimized and compiled model, along with a lightweight runtime inference engine provided by LEIP, is then deployed onto the edge device.
- Edge Inference: When new data is captured by the edge device's sensors, the optimized model performs inference directly on the device. Because the model is significantly smaller and more efficient, it runs much faster and consumes less power than the original model would.
- Output and Action: The device then uses the real-time inference results to make decisions, trigger actions, or send highly condensed insights back to the cloud.
LEIP's power lies in its ability to abstract away the complexities of low-level hardware optimization, allowing AI developers to focus on model development while trusting LEIP to deliver production-ready, efficient models for the edge.
💡 Why it’s hot:
Hardware-agnostic Edge AI enabler — LEIP (Latent AI Efficient Inference Platform) allows you to compress, quantize, and deploy AI models on virtually any constrained device without sacrificing accuracy. It's a powerful software platform designed to optimize existing neural networks for efficient execution on a wide range of edge hardware.
🚀 Use Cases:
- Battery-operated sensors: Enabling intelligent decision-making (e.g., anomaly detection in industrial sensors, agricultural pest identification) directly on low-power, remotely deployed devices, extending battery life and reducing data transmission.
- Automotive AI apps: Optimizing complex perception models (object detection, lane keeping, driver monitoring) for deployment on automotive-grade embedded processors, ensuring real-time performance and efficiency in ADAS and autonomous driving systems.
- TinyML at scale: Deploying highly efficient AI models onto microcontrollers and very low-power embedded systems for applications like keyword spotting, simple gesture recognition, or predictive maintenance in smart appliances and IoT devices, bringing AI to the smallest form factors.
- Consumer electronics: Integrating advanced AI features (e.g., on-device voice processing, personalized user experiences, gesture control) into wearables, smart speakers, and other devices with limited compute resources.
- Industrial IoT: Deploying AI for predictive maintenance on legacy industrial equipment, real-time quality inspection, or worker safety monitoring using existing camera infrastructure and low-power edge gateways.
🧠 Edge Advantage:
Software-driven edge optimization, bridging the gap between complex ML models and low-power hardware. LEIP focuses on making models dramatically smaller and faster without significant accuracy loss, unlocking AI capabilities for devices previously deemed unsuitable for machine learning.
Project 9: LatentAI LEIP™ Platform with Supported Hardware Codes:
🔗 View Project Code on GitHub🧠 LEIP Workflow Overview
You’re running a 4-phase ops cycle:
1. Profile the model
2. Optimize it (compression + quantization)
3. Deploy to the edge hardware
4. Run with LEIP runtime or convert to TFLite
💼 Supported Frameworks: TensorFlow, PyTorch, ONNX
⚙️ Target Platforms: ARM Cortex, x86, DSP, GPU, embedded AI SoCs
🔍 Bonus: Command Reference
|
Command |
Description |
|
|
Analyze model for edge suitability |
|
|
Compress, quantize, fuse operators |
|
|
Generate deployable edge binaries |
|
|
Convert formats (TFLite, ONNX, C-array) |
🔐 Supported Hardware Targets
· ARM Cortex-M / A
· Nvidia Jetson
· Sipeed K210 / Maix
· NXP i.MX RT
· Raspberry Pi
· x86 edge nodes
· TinyML platforms
📚 Need Resources?
https://github.com/onnx/models
🧬 10. Sipeed Maix Series (RISC-V Edge AI Boards)

Overview:
The Sipeed Maix series is a line of low-cost, high-performance embedded AI development boards built around the Kendryte K210 system-on-chip (SoC). The K210 is significant because it features a dual-core 64-bit RISC-V processor combined with a dedicated Neural Network Processor (KPU). This unique combination makes it highly capable of performing deep learning inference, particularly for computer vision tasks, directly at the edge. The "Maix" branding signifies its focus on AI applications ("AI" is pronounced similarly to "Ai" in Maix). The boards come in various form factors, from tiny modules for integration to full-featured development boards with screens, cameras, and microphones, catering to diverse project needs.
Benefits:
- Affordable Entry to Edge AI: One of the most cost-effective ways to get started with dedicated AI hardware, making it highly accessible for students, hobbyists, and budget-constrained projects.
- RISC-V Openness: Leveraging the open-source RISC-V instruction set architecture provides flexibility and transparency, appealing to developers who prefer open ecosystems and have long-term customization goals.
- Dedicated AI Acceleration (KPU): The integrated KPU (Kendryte Processing Unit) is specifically designed to accelerate convolutional neural networks (CNNs), enabling real-time object detection, facial recognition, and image classification on-device.
- Low Power Consumption: Designed for embedded applications, the K210 SoC consumes relatively low power, making it suitable for battery-powered projects.
- Integrated Peripherals: Many Maix boards come with essential peripherals like camera interfaces, LCD interfaces, and microphone arrays, simplifying the development of complete vision and audio AI applications.
- Community and Ecosystem: While newer than some competitors, it has a growing open-source community and toolchain support, including development environments, libraries, and examples.
- Learnable Platform: Its straightforward architecture and available resources make it an excellent platform for learning about embedded AI and RISC-V.
How it Works:
The Sipeed Maix series boards leverage the Kendryte K210 SoC's dual-core RISC-V CPU and dedicated KPU for edge AI inference:
- Model Training (Off-Device): Machine learning models (primarily CNNs for computer vision) are trained using popular frameworks like TensorFlow or PyTorch on a PC or cloud environment.
- Model Conversion and Optimization: The trained models are then converted and optimized for the KPU. Sipeed provides tools and documentation, often leveraging a custom toolkit, to quantize the models (typically to 8-bit integers) and compile them into a format that the KPU can efficiently execute. This optimization is crucial for achieving high performance on the embedded hardware.
- Deployment to Maix Board: The optimized AI model and the application code (often written in MicroPython or C) are flashed onto the Maix board's flash memory.
- Input Data Acquisition: A camera module connected to the Maix board captures raw image frames from the environment. Other sensors (e.g., microphones for audio processing) can also provide input.
- Data Pre-processing (CPU/KPU assist): The RISC-V CPU might handle some initial pre-processing of the input data (e.g., resizing, formatting) before it's fed to the KPU.
- AI Inference on KPU: The pre-processed data is then passed to the dedicated KPU. The KPU, with its specialized hardware accelerators, rapidly performs the complex matrix multiplications and convolutions required by the neural network layers, executing the AI inference at high speed.
- Output and Action (CPU Handling): The inference results (e.g., bounding box coordinates for detected objects, classification labels, confidence scores) are returned by the KPU to the RISC-V CPU. The CPU then processes these results. This might involve:
- Drawing bounding boxes on an attached LCD display.
- Sending data or commands over UART, SPI, or I2C to other components.
- Triggering an action based on the AI outcome (e.g., activating a servo, turning on an LED).
- Transmitting condensed data via Wi-Fi (on models with Wi-Fi).
- Software Development Environment: Development is typically done using an IDE like PlatformIO or a specific SDK provided by Sipeed, supporting MicroPython, C/C++, and often an easy-to-use API for interacting with the KPU.
The Sipeed Maix series provides a complete and accessible stack for exploring and deploying AI on RISC-V-based embedded systems, pushing the boundaries of what's possible at the very edge.
💡 Why it’s hot:
RISC-V-based edge AI — open-source hardware with dedicated AI coprocessors. The Sipeed Maix series stands out by bringing the flexibility and openness of the RISC-V instruction set architecture to accessible edge AI development, combining a powerful RISC-V CPU with a dedicated neural network accelerator.
🚀 Use Cases:
- DIY Embedded Vision: Building custom smart cameras, object counters, or automated sorting systems for home or small business applications with direct control over the hardware and software stack.
- Smart Home Security: Creating local, privacy-focused smart doorbells with facial recognition, motion-activated recording, or pet detection without relying on cloud services.
- Educational Kits: Serving as an ideal platform for teaching embedded systems, computer vision, and deep learning to students and hobbyists due to its affordability, open nature, and well-documented ecosystem.
- Industrial Sensor Nodes: Deploying intelligent sensors for basic anomaly detection, quality checks on production lines, or environmental monitoring where low cost and local processing are key.
- Robotics & Drones (basic vision): Providing lightweight vision capabilities for simple robot navigation, line following, or object identification in cost-sensitive robotic projects.
- Smart Appliances: Embedding AI for features like gesture control, food recognition in smart fridges, or personalized user interfaces in small consumer devices.
🧠 Edge Advantage:
Cheap, fast, and customizable. The RISC-V revolution begins at the edge. The Sipeed Maix series provides an open, powerful, and highly cost-effective entry point into embedded AI, fostering innovation and rapid prototyping without proprietary lock-in.
We’re talking neural nets in your palm, powered by KPU (Kendryte Processing Unit) and running at blazing speed — without the cloud, without excuses.
Let’s break down the codebase into two real-world flavors:
1. MaixPy — MicroPython with AI baked in
Maix C SDK — Hardcore embedded C/C++ for full control
Project 10: Sipeed Maix Series (RISC-V Edge AI Boards) Codes:
🔗 View Project Code on GitHub🔐 Common Use Cases:
· 📸 Real-time face & object detection
· 🔊 Voice command classification
· 📡 Remote AIoT sensors
· 🚀 Autonomous bots (cars, arms, drones)
🧰 Bonus: Tools You’ll Need
· 🔧 MaixPy IDE
· 🧠 Kmodel Zoo
· 💾 Kflash GUI
· 🔄 NNCase Compiler
🔮 Final Thought: The Edge is Thinking for Itself
Edge AI is more than just a buzzword; it's the defining movement of 2025, a profound revolution in decentralizing intelligence that is reshaping our technological landscape. No longer are the capabilities of neural networks tethered exclusively to distant cloud servers, subject to the whims of internet connectivity and the constraints of bandwidth. Instead, the "AI brain" has migrated directly to the point of action – residing on compact, purpose-built hardware found at the edge of farms, within autonomous vehicles, integrated into portable medical clinics, and embedded deep within the machinery of smart factories. This paradigm shift means real-time decisions can be made instantaneously, without the crippling delays of data round-trips to the cloud, fostering a new era of responsiveness and autonomy.
These ten hardware platforms, from NVIDIA's powerful Jetson Orin Nano to Google's efficient Coral Dev Board, Intel's versatile Myriad X VPUs, and the open-source spirit of Sipeed's Maix series, are the vanguards of this transformation. They are making the seemingly impossible a tangible reality, enabling sophisticated neural networks to perform complex analyses and make critical inferences directly on-device. This is where the tyranny of latency dies, replaced by the immediacy of real-time AI that powers safer transportation, more efficient industrial processes, personalized healthcare at the point of need, and unprecedented levels of automation in environments that demand robust, independent, and privacy-preserving intelligence. The world is witnessing intelligence truly think for itself, locally and instantly.
🚀 About This Program — Industry-Ready Data Science
By 2030, data won’t just inform decisions — it will drive them automatically. From fraud detection in milliseconds to personalized healthcare and real-time market forecasting, data science is the engine room of every intelligent system.
🛠️ The problem? Most programs throw you some Python scripts and drown you in Kaggle. But the industry doesn’t want notebook jockeys — it wants data strategists, model builders, and pipeline warriors who can turn chaos into insight, and insight into action.
🔥 That’s where Huebits flips the script.
We don’t train you to understand data science.
We train you to engineer it.
Welcome to a 6-month, hands-on, industry-calibrated Data Science Program — designed to take you from zero to deployable, from beginner to business-impacting. Whether it’s building scalable ML models, engineering clean data pipelines, or deploying predictions with APIs — you’ll learn what it takes to own the full lifecycle.
From mastering Python, Pandas, Scikit-learn, TensorFlow, and PyTorch, to building real-time dashboards, deploying on AWS, GCP, or Azure, and integrating with APIs and databases — this program equips you for the real game.
🎖️ Certification:
Graduate with the Huebits Data Science Engineering Credential — a mark of battle-tested ability, recognized by startups, enterprises, and innovation labs. This isn’t a pat on the back — it’s proof you can model, optimize, and deploy under pressure.
📌 Why This Program Hits Different:
Real-world, end-to-end Data Science & ML projects
Data pipeline building, model tuning, and cloud deployment
LMS access for a full year
Job guarantee upon successful completion
💥 Your future team doesn’t care if you’ve memorized the Titanic dataset —
They care how fast you can clean dirty data, validate a model, ship it to production, and explain it to the CEO.
Let’s train you to do exactly that.
🎯 Join Huebits’ Industry-Ready Data Science Program
and build a career powered by precision, insight, and machine learning mastery.
Line by line. Model by model. Decision by decision.
🔥 "Take Your First Step into the Data Science Revolution!"
Ready to turn raw data into intelligent decisions, predictions, and impact? From fraud detection to recommendation engines, real-time analytics to AI-driven automation — data science is the brain behind today’s smartest systems.
Join the Huebits Industry-Ready Data Science Program and get hands-on with real-world datasets, model building, data pipelines, and full-stack deployment — using the same tech stack trusted by global data teams and AI-first companies.
✅ Live Mentorship | 🧠 Industry-Backed ML Projects | ⚙️ Deployment-Ready, Career-Focused Curriculum
